蚂蚁KAG框架核心功能研读
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
作者介绍:
薛明:拥有近10年在医疗和零售领域应用机器学习和人工智能的经验。曾就职于通用电气、复星医药等企业。长期专注于医学图像、自然语言处理以及数据科学的研发工作,如训练/推理框架、数据挖掘与分析等领域。于2024年7月创立AI公司Percena,负责基于大模型的应用产品开发,如RAG&Agent等。
编者语 :
结识薛明同学,来自今年七月份他撰写的 《微软GraphRAG框架源码解读》 一文,发现他对知识图谱+大模型结合技术有着浓厚的兴趣。后来我就邀请他参与到DB-GPT的GraphRAG功能建设中来,为 图社区摘要能力增强 这个特性提供了诸多有价值技术思路和和代码贡献。这次正值蚂蚁知识图谱团队的KAG框架开源,薛明又以“雷厉风行”之势对其框架源码进行了深度解读,对于蚂蚁TuGraph和OpenSPG开源社区,我们为拥有这样的社区贡献者和合作伙伴感到欣喜自豪,或许这就是开源的魅力。
另外,11.9日蚂蚁DB-GPT、TuGraph、OpenSPG三大开源社区会在上海S空间举办联合Meetup 《大模型背景下的私域知识库构建和可信问答》 ,我们为大家准备了大量的技术干货和场景案例分享,欢迎小伙伴们前来报名围观。11.15日我和薛明会在 全球机器学习大会 上给出联合演讲《Graph+AI:立足DB-GPT社区探索GraphRAG未来架构》,分享我们在共建DB-GPT GraphRAG时的开源社区合作细节和心得体会。
1. 引言
前几天蚂蚁正式发布了一个专业领域知识服务框架, 叫做知识增强生成(KAG:Know+ledge Augmented Generation),该框架旨在充分利用知识图谱和向量检索的优势,以解决现有 RAG 技术栈的一些挑战。
从蚂蚁对这个框架预热开始,笔者就对 KAG 的一些核心功能比较感兴趣,尤其是逻辑符号推理与知识对齐,在现有主流 RAG 系统中,这两点讨论貌似还不算多,趁着这次开源,赶紧研究一波。
-
KAG论文地址: https://arxiv.org/pdf/2409.13731
-
KAG项目地址: https://GitHub.com/OpenSPG/KAG
2. 框架概述
具体研读代码前,我们还是先简单了解下框架的目标与定位。
2.1 解决了什么问题( What & Why)?
其实看到 KAG 这个框架,我相信很多人估计跟我一样,想到的第一个问题就是为什么不叫 RAG 改叫 KAG 了。根据相关文章与论文,KAG 框架主要是为了解决当前大模型在专业领域知识服务中面临的一些挑战:
- LLM 不具备严谨的思考能力,推理能力缺失
- 事实、逻辑、精准性错误,无法使用预定义的领域知识结构来约束模型的行为
- 通用 RAG 也难以解决 LLM 幻觉问题,尤其是隐蔽的误导性信息
- 专业知识服务的挑战和要求,缺乏严格且可控的决策过程
因此,蚂蚁团队认为,一个专业的知识服务框架,必须具备以下几个特点:
- 必须确保知识的准确性,包括知识边界的完整性、知识结构和语义的清晰性;
- 需要具备逻辑严谨性、时间敏感性和数字敏感性;
- 还需要完备的上下文信息,以方便在知识决策时获取完备的支持信息;
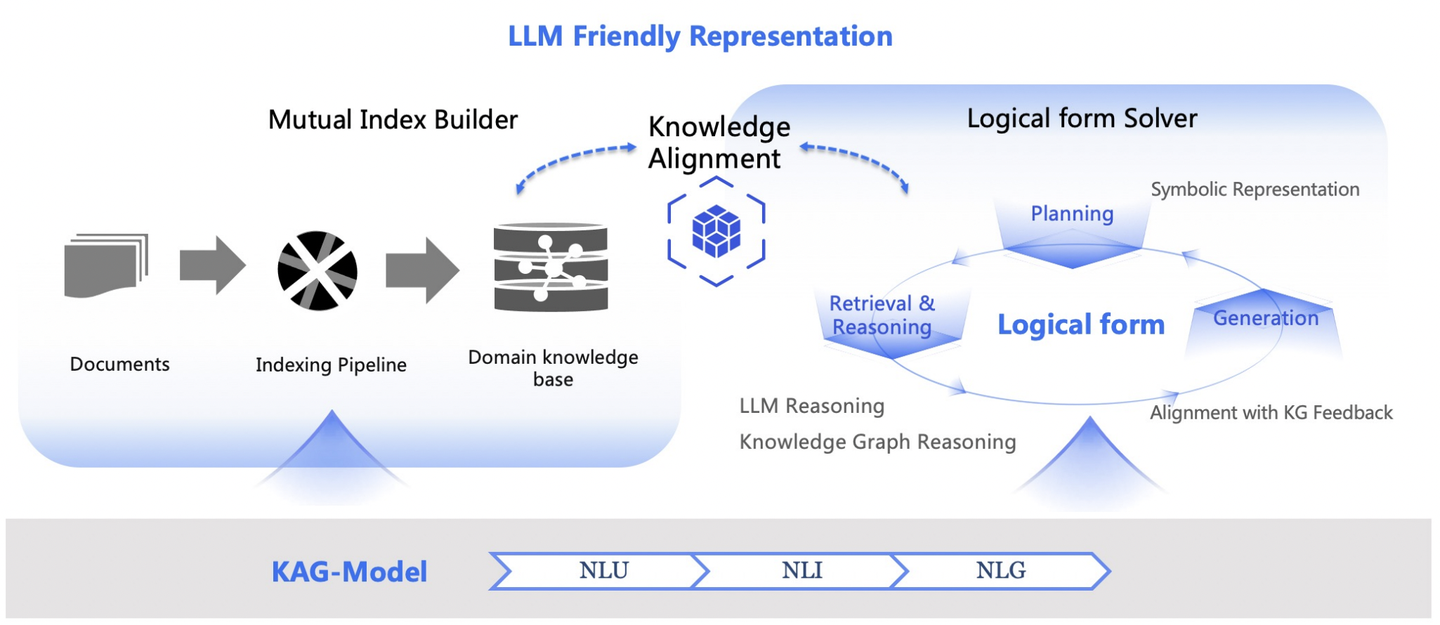
蚂蚁官方对 KAG 的定位是: 专业领域知识增强服务框架, 具体针对当前大语言模型与知识图谱结合对以下五个方面进行了增强
- 对 LLM 友好的知识表示增强
- 知识图谱与原文片段之间的互索引结构
- 逻辑符号引导的混合推理引擎
- 基于语义推理的知识对齐机制
- KAG 模型
这次开源完整涵盖了前面 4 项核心特性。
回到 KAG 命名的问题上,个人推测可能还是为了强化知识本体的概念。从官方描述以及实际代码实现来看,KAG 框架无论在构建还是推理阶段,都在不断强调从知识本身出发,构建完整严谨的逻辑链路,以尽可能改善 RAG 技术栈的一些已知问题。
2.2 实现方式是什么(How)?
KAG 框架由三部分组成:KAG-Builder、KAG-Solver 和 KAG-Model:
- KAG-Builder 用于离线索引,主要包括上述提到的特性 1 和 2:知识表示增强、互索引结构。
- KAG-Solver 模块涉及特性 3 和 4:逻辑符号混合推理引擎、知识对齐机制。
- KAG-Model 则尝试构建了一个端到端的 KAG 模型。
3. 源码解析
这次开源主要涉及 KAG-Builder 和 KAG-Solver 两个模块,直接对应源码中的 builder 与 solver 两个子目录。
实际研读代码过程中,建议先从
examples
目录入手,了解下整个框架的运行流程,然后再深入到具体模块。几个 Demo 的入口文件路径都差不多,比如
kag/examples/medicine/builder/indexer.py
以及
kag/examples/medicine/solver/evaForMedicine.py
,可以清楚看出 builder 组合了不同的模块,而 solver 的真正入口位于
kag/solver/logic/solver_pipeline.py
。
3.1 KAG-Builder
先贴一下完整目录结构
❯ tree .
.
├── __init__.py
├── comPONEnt
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
Builder 部分涉及的功能较多,这里仅探讨一个比较关键的组件
KAGExtractor
,其基本流程图如下:
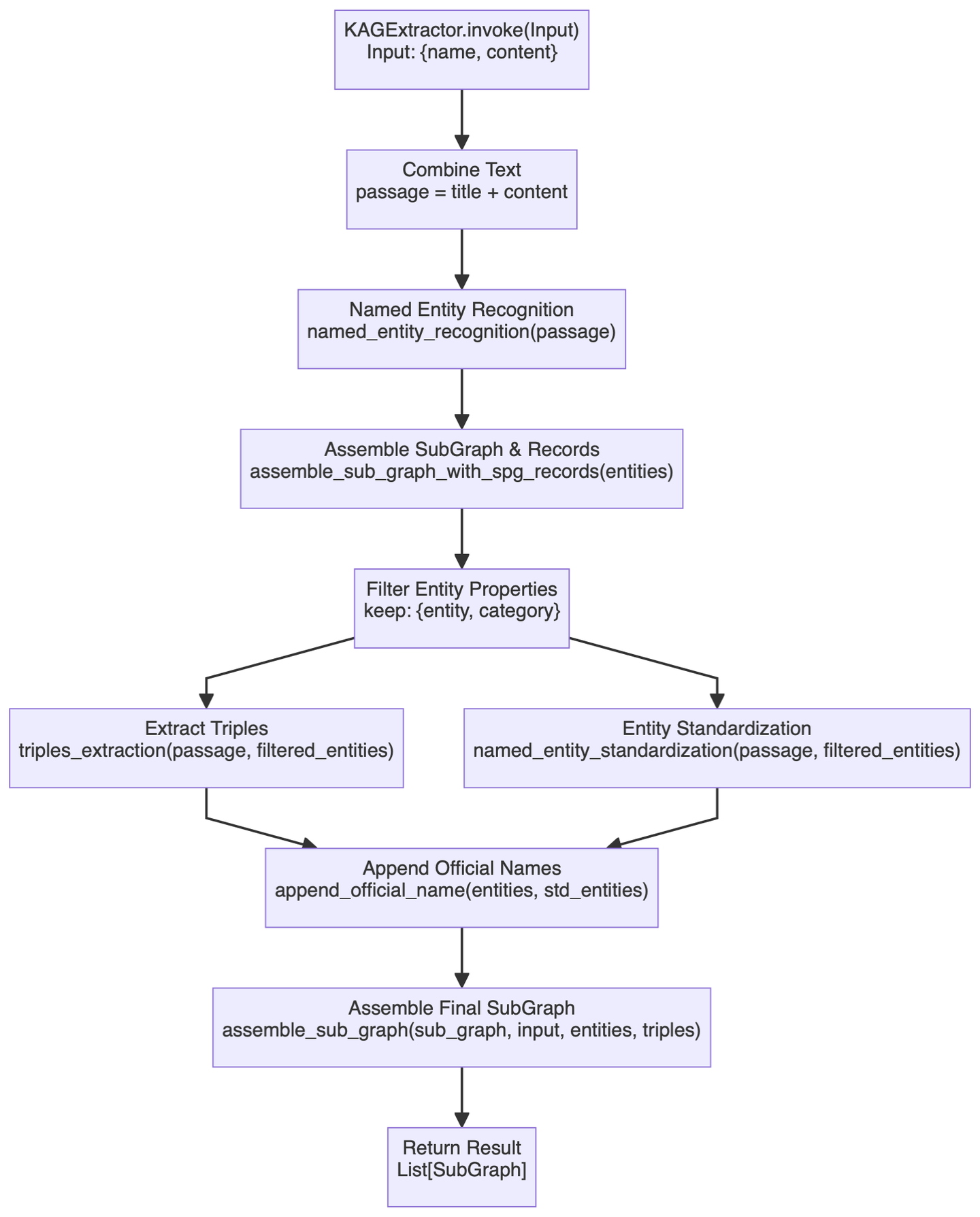
这里主要在做的就是利用大模型,实现了从非结构化文本到结构化知识图谱的自动创建,简单描述下其中的一些重要步骤。
-
首先是实体识别模块,这里会针对预定义的知识图谱类型先进行特定实体识别,然后进行通用命名实体识别。这种双层识别机制应该能够确保既能捕获领域特定的实体,又不会遗漏通用实体。
-
图谱构建过程实际是由
assemble_sub_graph_with_spg_records方法完成的,它的特殊之处在于,系统会将非基本类型的属性转换为图中的节点和边,而不再是继续保留为实体的原有属性。这一点的改动说实话没有很理解,一定程度上应该是简化了实体的复杂性的,但实际还不太清楚这种策略能带来多大的收益,构建的复杂度肯定是增加了。 -
实体标准化由
named_entity_standardization和append_official_name两个方法协同完成。首先对实体名称进行规范化处理,然后将这些标准化的名称与原始实体信息进行关联。这个过程感觉上类似于实体去重(Entity Resolution)。
整体来说,Builder 模块的功能跟目前常见的图谱构建技术栈还算比较接近,相关文章与代码理解起来难度也不太大,此处不再赘述。
3.2 KAG-Solver
Solver 部分涉及到整个框架的很多核心功能点,尤其是逻辑符号推理相关内容,先看下整体结构:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_Plan+er.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
之前提到 solver 的入口文件,这里贴下相关代码:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# AttEMPt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
整个
SolverPipeline.run()
方法主要涉及 3 个模块:
Reasoner
,
Reflector
和
Generator
,其整体逻辑还是很清晰的:先尝试解答,然后反思问题是否已得到解决,如果没有则继续深入思考,直到得到满意的答案或达到最大尝试次数。基本算是模仿人类解决复杂问题的一般思考方式。
以下部分对上述 3 个模块进一步分析。
3.3 Reasoner
推理模块可能是整个框架最复杂的部分了,其关键代码如下:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical foRMS to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A Dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
由此绘制出推理模块的整体流程图:(已省略错误处理等逻辑)
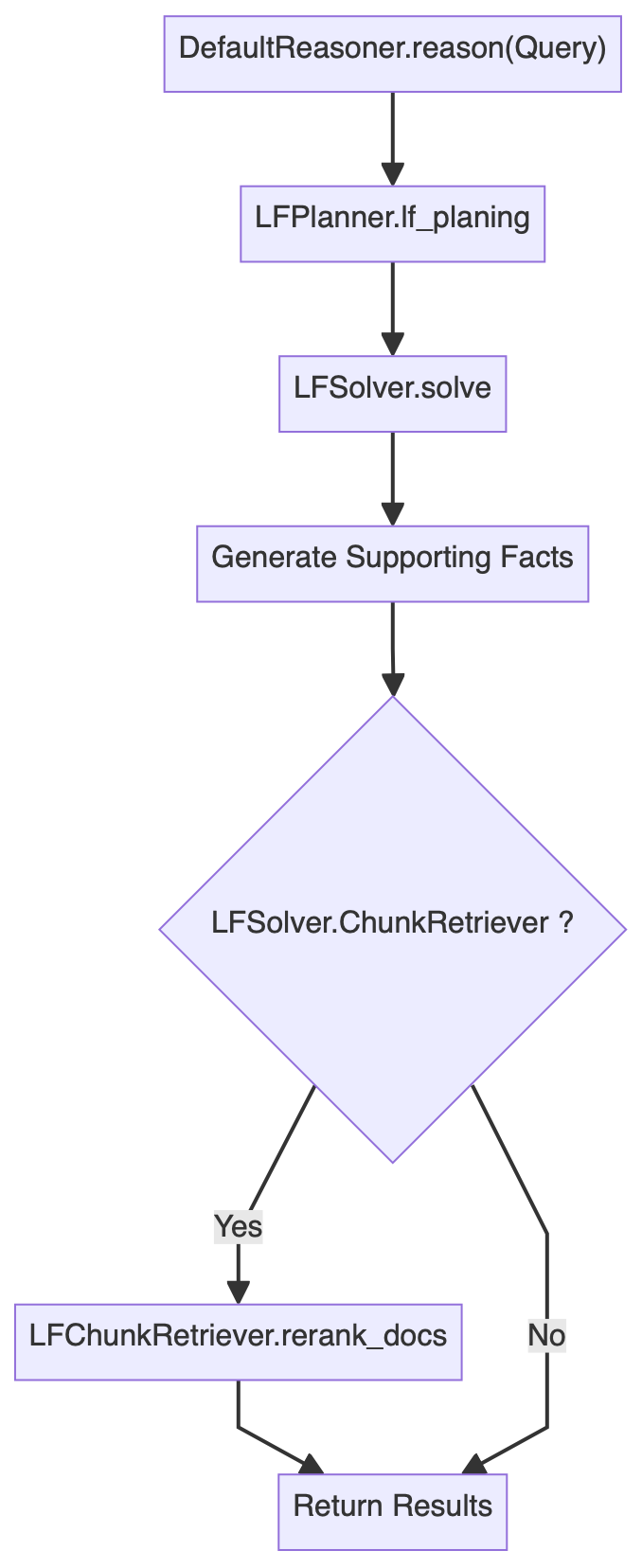
容易看出,
DefaultReasoner.reason()
方法大体分为三个步骤:
-
逻辑形式规划 (Logic Form Planning):主要涉及
LFPlanner.lf_planing -
逻辑形式执行 (Logic Form Execution):主要涉及
LFSolver.solve -
文档重排序 (Document Reranking):主要涉及
LFSolver.chunk_retriever.rerank_docs
以下分别对三个步骤进行详细分析。
3.3.1 逻辑形式规划 (Logic Form Planning)
DefaultLFPlanner.lf_planing()
方法主要用于将查询分解为一系列独立的逻辑形式(
lf_nodes: List[LFPlanResult]
)。
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
其具体实现逻辑可参考
kag/solver/implementation/default_lf_planner.py
,主要是针对
llm_output
做正则化解析,如果未提供则调用 LLM 生成新的逻辑形式。
这里可以关注下
kag/solver/prompt/default/logic_form_plan.py
中有关
LogicFormPlanPrompt
的详细设计,其核心在于如何将复杂问题分解为多个子查询以及对应的逻辑形式。
3.3.2 逻辑形式执行 (Logic Form Execution)
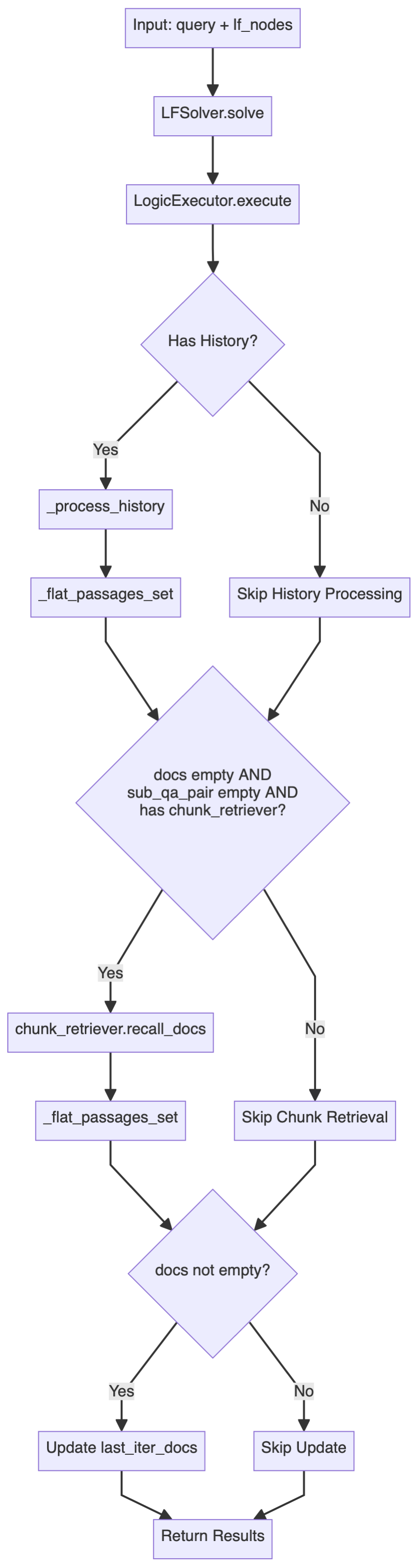
LFSolver.solve()
方法用于求解具体逻辑形式问题,返回答案、子问题答案对、相关召回文档和历史记录等。
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
深入
kag/solver/logic/core_modules/lf_solver.py
源码部分,可以发现
LFSolver
类(逻辑形式求解器)是整个推理过程的核心类,负责执行逻辑形式(LF)并生成答案:
-
其主要方法是
solve,接收一个查询和一组逻辑形式节点(List[LFPlanResult])。 -
使用
LogicExecutor来执行逻辑形式,生成答案、知识图谱路径和历史记录。 - 处理子查询和答案对,以及相关文档。
-
错误处理和回退策略:如果没有找到答案或相关文档,会尝试使用
chunk_retriever召回相关文档。
其主要流程如下:
其中
LogicExecutor
是比较关键的一个类,这里贴一下核心代码:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
-
执行逻辑
LogicExecutor类的相关代码位于kag/solver/logic/core_modules/lf_executor.py。其execute方法的主要执行流程如下图所示: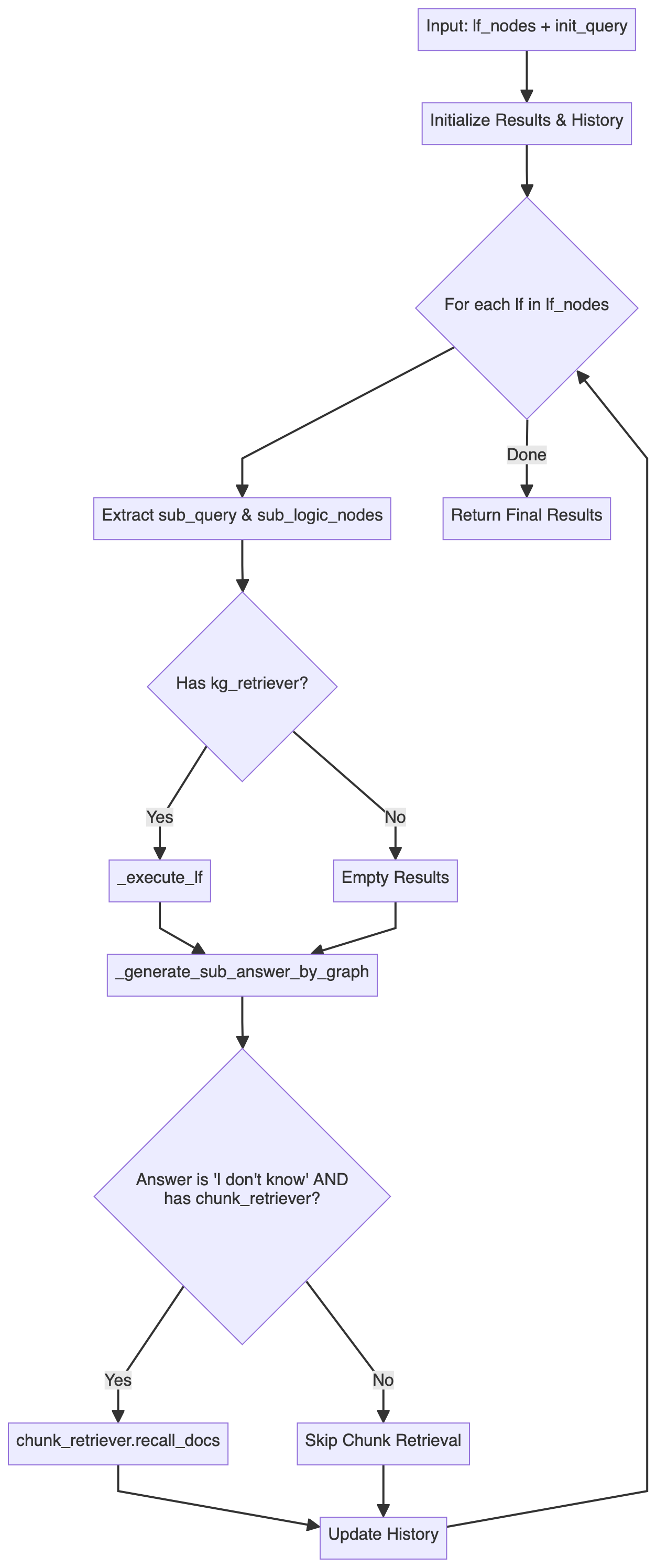
这个执行流程展示了一套双重检索策略: 优先使用结构化的图谱数据检索和推理,当图谱无法回答时,回退到非结构化文本信息检索。
系统首先尝试通过知识图谱解答问题,对每个逻辑表达式节点,通过不同的执行器(涉及
deduce、math、sort、retrieval、output等操作)进行处理,检索过程会收集 SPO(主谓宾)三元组,用于后续的答案生成;当图谱无法提供满意答案时(返回"I don't know"),系统会回退到文本块检索:利用之前获取的命名实体(NER)结果作为检索锚点,结合历史问答记录构建上下文增强的查询,再通过chunk_retriever基于检索得到的文档重新生成答案。整个过程可以看作是一个优雅的降级策略,通过结合结构化的知识图谱和非结构化的文本数据,这种混合检索能够在保证准确性的同时,尽可能地提供完整且上下文连贯的答案。
-
核心组件
除了上述具体的执行逻辑外,注意到
LogicExecutor初始化时需要传入多个组件。限于篇幅,这里仅简单描述下各组件的核心功能,具体实现可参考源码。-
kg_retriever: 知识图谱检索器
参考
kag/solver/implementation/default_kg_retrieval.py中KGRetrieverByLlm(KGRetrieverABC),实现了实体与关系的检索,涉及精确/模糊、一跳子图等多种匹配方式。 -
chunk_retriever: 文本块检索器
参考
kag/common/retriever/kag_retriever.py中DefaultRetriever(ChunkRetrieverABC),这里的代码值得好好研究一下,首先在 Entity 处理方面做了标准化操作,此外,此处的检索参考了 HippoRAG,采用了 DPR (Dense Passage Retrieval) 和 PPR (Personalized PageRank) 相结合的混合检索策略,后续还进一步基于 DPR 与 PPR 的 Score 进行了融合,实现了两种检索的动态权重分配。 -
entity_linker (el): 实体链接器
参考
kag/solver/logic/core_modules/retriver/entity_linker.py中DefaultEntityLinker(EntityLinkerBase),这里采用了先构建特征再并行化处理实体链接的思路。 -
dsl_runner: 图数据库查询器
参考
kag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.py中DslRunnerOnGraphStore(DslRunner),负责将结构化的查询信息转换为具体的图数据库查询语句,这块会涉及底层具体的图数据库,细节相对繁杂,就不过多涉及了。
-
通过梳理上述代码与流程图,可以看出,整个逻辑形式执行 (Logic Form Execution) 环节采用了分层处理架构:
-
顶层
LFSolver负责整体流程 -
中间层
LogicExecutor负责执行具体逻辑形式(LF) -
底层
DSL Runner负责与图数据库交互
3.3.3 文档重排序 (Document Reranking)
如果启用了
chunk_retriever
,还会对召回文档进行重排序。
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 Reflector
Reflector
类主要实现了
_can_answer
与
_refine_query
两个方法,前者用于判断是否可以回答问题,后者用于优化多跳查询的中间结果,以引导最终答案的生成。
相关实现参考
kag/solver/prompt/default/resp_judge.py
与
kag/solver/prompt/default/resp_reflector.py
这两个 Prompt 文件更容易理解。
3.5 Generator
主要是
LFGenerator
类,根据不同场景(有无知识图谱、有无文档等)动态选择提示词模板,并生成对应问题的答案。
相关实现位于
kag/solver/logic/core_modules/lf_generator.py
,代码相对直观,不再赘述。
4. 一些思考
蚂蚁这次开源的 KAG 框架,主打专业领域知识增强服务,涵盖了符号推理、知识对齐等一系列创新点,综合研读下来,个人感觉该框架尤其适合需要 严格约束 Schema 的专业知识场景,无论是在索引还是查询阶段,整个工作流都在反复强化一种观点:必须从受约束的知识库出发,去构建图谱或做逻辑推理。这种思路应该可以一定程度上缓解大模型领域知识缺失以及幻觉的问题。
微软的 GraphRAG 框架自开源以来,社区对于知识图谱与 RAG 技术栈的融合有了更多的思考,比如近期的 LightRAG、StructRAG 等工作,都做了很多有益的探索。KAG 虽然在技术路线上与 GraphRAG 存在一定差异,但也一定程度上可以看作是 GraphRAG 在专业领域知识增强服务方向上的一次实践,尤其是补齐了知识对齐与推理方面的短板。从这个角度来说,我个人其实更愿意称之为 Knowledge constrained GraphRAG。
原生 GraphRAG,依据不同社区进行分层摘要,从而可以回答相对抽象的 high level 的问题,不过也正因为对于 Query-focused summarization (QFS) 的过度关注,导致该框架在细颗粒度事实性问题上可能表现不佳,再考虑到成本问题,原生 GraphRAG 在垂域落地方面还存在很多挑战,而 KAG 框架从图谱构建阶段就做了比较多的优化,比如基于特定 Schema 的 Entity 对齐与标准化操作,在查询阶段,还引入了基于符号逻辑的知识图谱推理方法,符号推理虽然在图谱领域研究已经比较多了,不过真正应用到 RAG 场景好像还不多见。RAG 推理能力的强化是笔者比较看好的一个研究方向,前段时间微软总结了 RAG 技术栈推理能力的 4 个层级:
- Level-1 Explicit Facts,显性事实
- Level-2 Implicit Facts,隐性事实
- Level-3 Interpretable Rationales,可解释(垂域)理由
- Level-4 Hidden Rationales,隐形(垂域)理由
目前大部分 RAG 框架的推理能力还仅限于 Level-1 层级,上述的 Level-3 与 Level-4 层级就强调了垂域推理的重要性,其难点在于大模型在垂域知识的缺失,本次 KAG 框架在查询阶段引入符号推理,一定程度上可以看作是对此方向的探索,可预见的是 RAG 推理方面后续可能会掀起一波新的研究热潮,比如进一步融合模型本身的推理能力,如 RL 或者 CoT 等,现阶段已有的一些尝试工作在场景落地方面还多少存在限制。
除了推理环节,KAG 在 Retrieval 方面参考 HippoRAG 采用了 DPR 与 PPR 混合检索策略,PageRank 的高效使用,也进一步展示了知识图谱相对传统向量检索的优势,相信今后会有更多的图谱检索算法被集成到 RAG 技术栈中。
当然,KAG 框架目前估计仍处于早期快速迭代阶段,在功能具体实现方面应该还是存在一定的讨论空间,比如现有的逻辑形式规划 (Logic Form Planning) 以及逻辑形式执行 (Logic Form Execution) 在设计层面是否有完备的理论支撑,在面对复杂问题时,是否会出现分解不充分、执行失败的情况,不过这种边界界定以及鲁棒性问题通常处理起来都非常困难,也需要大量的试错成本,如果整个推理链路过于复杂,最终失败率可能确实会比较高,毕竟各种降级回退策略也只是一定程度上缓解问题。此外,笔者注意到,框架底层的 GraphStore 其实已经预留了增量更新接口,但是上层应用并未展示出相关能力,这一块也是个人了解到的 GraphRAG 社区呼声比较高的一个特性。
综合来看,KAG 框架算是近期非常硬核的工作,包含了大量创新点,代码方面也确实做了很多细节方面的打磨,相信对于 RAG 技术栈的落地进程会是一个重要的推动。
5. Reference
- 国内首个专业领域知识增强服务框架 KAG 技术报告,助力大模型落地垂直领域
- 突破 RAG 局限,KAG 专业领域知识服务框架正式开源!
- KAG Boosting LLMs in Professional Domains via Knowledge Augmented Generation
- kag-solver 扩展
- microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system
- OSU-NLP-Group/HippoRAG: [NeurIPS'24] HippoRAG is a novel RAG framework inspired by human long-term memory that enables LLMs to continuously integrate knowledge across external documents. RAG + Knowledge Graphs + Personalized PageRank.
- Retrieval Augmented Generation (RAG) and Beyond A Comprehensive Survey on How to Make your LLMs use External Data More Wisely


































- 1
玻璃人射击逃亡
- 2
地铁跑酷主播同款直充版下载 v5.04.0 安卓版
- 3
新麻将连连看 消消乐
- 4
托卡3D版全部版中文版下载 v2.2.2 安卓版
- 5
天天酷跑3d单机游戏
- 6
雪中天刀行 官网下载
- 7
植物大战僵尸杂交版 安卓正版
- 8
茶香世家
- 9
植物大战僵尸杂交版 最新免费下载
- 10
人类游乐场 安卓免费版
 玻璃人射击逃亡
玻璃人射击逃亡 地铁跑酷主播同款直充版下载 v5.04.0 安卓版
地铁跑酷主播同款直充版下载 v5.04.0 安卓版 新麻将连连看 消消乐
新麻将连连看 消消乐 托卡3D版全部版中文版下载 v2.2.2 安卓版
托卡3D版全部版中文版下载 v2.2.2 安卓版 天天酷跑3d单机游戏
天天酷跑3d单机游戏 雪中天刀行 官网下载
雪中天刀行 官网下载 植物大战僵尸杂交版 安卓正版
植物大战僵尸杂交版 安卓正版 茶香世家
茶香世家 植物大战僵尸杂交版 最新免费下载
植物大战僵尸杂交版 最新免费下载 人类游乐场 安卓免费版
人类游乐场 安卓免费版- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
捕鱼大世界 无限金币版
- 4
企鹅岛 官方正版中文版
- 5
内蒙打大a真人版
- 6
跳跃之王手游
- 7
情商天花板 2024最新版
- 8
球球英雄 手游
- 9
烦人的村民 手机版
- 10
大富翁go 官网版
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 内蒙打大a真人版
内蒙打大a真人版 跳跃之王手游
跳跃之王手游 情商天花板 2024最新版
情商天花板 2024最新版 球球英雄 手游
球球英雄 手游 烦人的村民 手机版
烦人的村民 手机版 大富翁go 官网版
大富翁go 官网版