使用Python和Selenium采集动态网页信息的方法
时间:2024-11-01 09:48:02来源:Lwgzc手游网作者:佚名我要评论 用手机看

扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
--- 好的方法很多,我们先掌握一种 ---
【背景】
对于网页信息的采集,静态页面我们通常都可以通过Python的request.get()库就能获取到整个页面的信息。
但是对于动态生成的网页信息来说,我们通过request.get()是获取不到。
【方法】
可以通过Python第三方库Selenium来配合实现信息获取,采取方案:Python + request + Selenium + BeautifulSoup
我们拿纵横中文网的小说采集举例(注意:请查看网站的robots协议找到可以爬取的内容,所谓盗亦有道):
思路整理:
1. 通过Selenium 定位元素的方式找到小说章节信息
2. 通过BeautifulSoup加工后提取章节标题和对应的各章节的链接信息
3. 通过request + BeautifulSoup 按章节链接提取小说内容,并将内容存储下来
【上代码】
1. 先在开发者工具中,调试定位所需元素对应的xpath命令编写方式
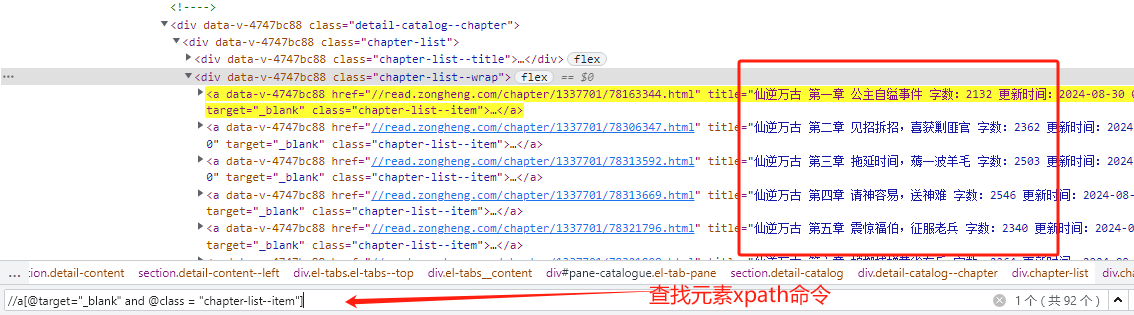
2. 通过Selenium 中find_elements()定位元素的方式找到所有小说章节,我们这里定义一个方法接受参数来使用
3. 把采集到的信息通过BeautifulSoup加工后,提取章节标题和链接内容
4. 通过request + BeautifulSoup 按章节链接提取小说内容,并保存到一个文件中
热门手游下载
 三国志9 安卓版中文版
三国志9 安卓版中文版 神笔作文批改
神笔作文批改 犯罪现场清洁工 手机免费版
犯罪现场清洁工 手机免费版 Dummynation 安卓手机版
Dummynation 安卓手机版 小熊寿司吧 官网汉化版
小熊寿司吧 官网汉化版 玩偶火柴人沙盒
玩偶火柴人沙盒 网吧老板模拟器2 完整版
网吧老板模拟器2 完整版 骗子酒馆 手机下载汉化版
骗子酒馆 手机下载汉化版 极速赛车驾驶
极速赛车驾驶 可口的咖啡美味的咖啡安卓版
可口的咖啡美味的咖啡安卓版 暗影格斗2 官方正版入口
暗影格斗2 官方正版入口 莫比乌斯旋律
莫比乌斯旋律 植物大战僵尸融合版 下载链接
植物大战僵尸融合版 下载链接 工匠与旅人
工匠与旅人
相关文章
- 全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
- 逻辑回归模型原理及Python实现
- Python中引用不确定的函数详解及示例
- [python] Python日志记录库loguru使用指北
- 使用Python开发一个支持etcd集群的SDK
- Python 潮流周刊#55:分享 9 个高质量的技术类信息源!
- Python 正则表达式大揭秘应用与技巧全解析
- 如何通过python预测下一组数据?
- 微信跳一跳python怎么刷分 python脚本刷分技巧
- visual studio code如何运行python 扩展帮你忙
- python如何安装模块 模块安装操作教程
- 授权服务和API接口的使用说明
热门文章


热门手游推荐
换一批


















- 1
违和感推理游戏
- 2
玻璃人射击逃亡
- 3
地铁跑酷主播同款直充版下载 v5.04.0 安卓版
- 4
新麻将连连看 消消乐
- 5
托卡3D版全部版中文版下载 v2.2.2 安卓版
- 6
天天酷跑3d单机游戏
- 7
雪中天刀行 官网下载
- 8
植物大战僵尸杂交版 安卓正版
- 9
茶香世家
- 10
植物大战僵尸杂交版 最新免费下载
 违和感推理游戏
违和感推理游戏 玻璃人射击逃亡
玻璃人射击逃亡 地铁跑酷主播同款直充版下载 v5.04.0 安卓版
地铁跑酷主播同款直充版下载 v5.04.0 安卓版 新麻将连连看 消消乐
新麻将连连看 消消乐 托卡3D版全部版中文版下载 v2.2.2 安卓版
托卡3D版全部版中文版下载 v2.2.2 安卓版 天天酷跑3d单机游戏
天天酷跑3d单机游戏 雪中天刀行 官网下载
雪中天刀行 官网下载 植物大战僵尸杂交版 安卓正版
植物大战僵尸杂交版 安卓正版 茶香世家
茶香世家 植物大战僵尸杂交版 最新免费下载
植物大战僵尸杂交版 最新免费下载- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
捕鱼大世界 无限金币版
- 4
企鹅岛 官方正版中文版
- 5
内蒙打大a真人版
- 6
跳跃之王手游
- 7
情商天花板 2024最新版
- 8
球球英雄 手游
- 9
烦人的村民 手机版
- 10
大富翁go 官网版
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 内蒙打大a真人版
内蒙打大a真人版 跳跃之王手游
跳跃之王手游 情商天花板 2024最新版
情商天花板 2024最新版 球球英雄 手游
球球英雄 手游 烦人的村民 手机版
烦人的村民 手机版 大富翁go 官网版
大富翁go 官网版