K-means聚类算法及其应用
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
K-means聚类是一种非常流行的聚类算法,它的目标是将n个样本划分到k个簇中,使得每个样本属于与其最近的均值(即簇中心)对应的簇,从而使得簇内的方差最小化。K-means聚类算法简单、易于实现,并且在许多应用中都非常有效。
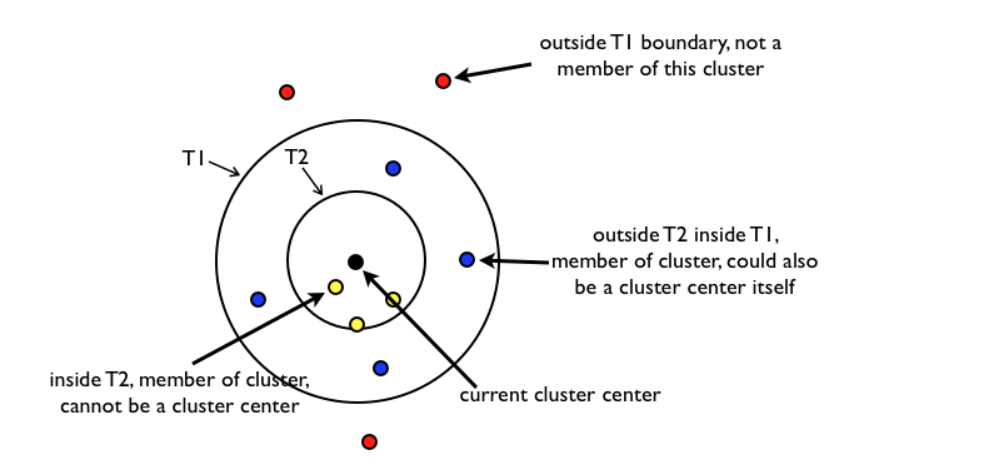
K-means算法的基本步骤:
选择初始中心:随机选择k个样本点作为初始的簇中心,或者使用K-means++算法来更智能地选择初始簇中心。
分配样本:将每个样本点分配到最近的簇中心,形成k个簇。
更新簇中心:重新计算每个簇的中心,通常是簇内所有点的均值。
迭代优化:重复步骤2和3,直到簇中心不再发生显著变化,或者达到预设的迭代次数。
终止条件:当簇中心在连续迭代中的变化小于某个阈值,或者达到预设的最大迭代次数时,算法终止。
K-means算法的数学表示:
设 C={c1,c2,...,ck}C={c1,c2,...,ck} 为簇中心的集合,X={x1,x2,...,xn}X={x1,x2,...,xn} 为样本点集合。
K-means的目标是最小化簇内误差平方和(Within-Cluster Sum of Squares, WCSS):
J(C)=∑i=1k∑x∈Si∣∣x−ci∣∣2J(C)=∑i=1k∑x∈Si∣∣x−ci∣∣2
其中,SiSi 是簇 cici 中的样本点集合。
K-means算法的优缺点:
优点:
- 算法简单,易于理解和实现。
- 在处理大数据集时,计算效率较高。
- 可以用于发现任意形状的簇。
缺点:
- 需要预先指定 k值 ,而k值的选择可能依赖于领域知识或试错。
- 对初始簇中心的选择敏感,可能导致局部最优解。
- 对噪声和异常点敏感,可能影响簇中心的计算。
- 只能发现数值型特征的簇,不适合文本数据等非数值型数据。
K-means++算法:
K-means++是一种改进的K-means算法,用于更智能地选择初始簇中心,从而提高聚类的质量。K-means++的基本思想是:
- 随机选择一个点作为第一个簇中心。
- 对于每个剩余的点,计算其到最近簇中心的距离,并根据距离的平方选择下一个簇中心。
- 重复步骤2,直到选择k个簇中心。
实际应用:
K-means聚类可以应用于多种场景,包括但不限于:
- 市场细分:根据客户的特征将客户分组。
- 图像分割:将图像分割成不同的区域或对象。
- 社交网络分析:发现社交网络中的社区结构。
- 文本聚类:对文档或新闻文章进行分组。
K-means聚类是一种非常实用的工具,但需要根据具体问题和数据集的特性来调整和优化。
下面是一个简单的Java实现K-means聚类算法的示例代码。这个示例将演示如何使用K-means算法对一组二维点进行聚类。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
public class KMeansClustering {
static class Point {
double x, y;
Point(double x, double y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return String.format("(%f, %f)", x, y);
}
}
public static void kMeans(List<Point> points, int k, int maxIterations) {
Random rand = new Random();
List<Point> centroids = new ArrayList<>();
// 初始化质心
for (int i = 0; i < k; i++) {
centroids.add(points.get(rand.nextInt(points.Size())));
}
for (int iter = 0; iter < maxIterations; iter++) {
// 1. 将每个点分配到最近的质心
List<List<Point>> clusters = new ArrayList<>();
for (int i = 0; i < k; i++) {
clusters.add(new ArrayList<>());
}
for (Point point : points) {
double minDistance = Double.MAX_VALUE;
int closestCentroid = 0;
for (int j = 0; j < k; j++) {
double dist = point.distance(centroids.get(j));
if (dist < minDistance) {
minDistance = dist;
closestCentroid = j;
}
}
clusters.get(closestCentroid).add(point);
}
// 2. 更新质心
boolean changed = false;
List<Point> newCentroids = new ArrayList<>();
for (List<Point> cluster : clusters) {
if (cluster.isEMPty()) {
newCentroids.add(centroids.get(0)); // 如果某个簇为空,随机选择一个质心
changed = true;
} else {
Point newCentroid = cluster.get(0);
for (Point point : cluster) {
newCentroid = new Point(
newCentroid.x / cluster.size() + point.x / cluster.size(),
newCentroid.y / cluster.size() + point.y / cluster.size()
);
}
newCentroids.add(newCentroid);
}
}
// 检查质心是否变化,如果没有则停止迭代
if (!changed && centroids.equals(newCentroids)) {
break;
}
centroids.clear();
centroids.addAll(newCentroids);
}
// 输出最终的质心和簇
for (int i = 0; i < centroids.size(); i++) {
System.out.println("Centroid " + i + ": " + centroids.get(i));
System.out.print("Cluster " + i + ": ");
for (Point point : clusters.get(i)) {
System.out.print(point + " ");
}
System.out.println();
}
}
public static void main(String[] args) {
List<Point> points = new ArrayList<>();
points.add(new Point(1.0, 2.0));
points.add(new Point(1.5, 1.8));
points.add(new Point(5.0, 8.0));
points.add(new Point(8.0, 8.0));
points.add(new Point(1.0, 0.6));
points.add(new Point(9.0, 11.0));
points.add(new Point(8.0, 2.0));
points.add(new Point(10.0, 2.0));
points.add(new Point(9.0, 3.0));
int k = 3; // 簇的数量
int maxIterations = 100; // 最大迭代次数
kMeans(points, k, maxIterations);
}
}
解释说明:
-
Point类:一个简单的Point类,包含x和y坐标,并重写了toString方法以便于打印。
-
kMeans方法:
分配点到最近的质心:对于每个点,计算其到每个质心的距离,并将点分配到最近的质心所代表的簇。
更新质心:计算每个簇所有点的均值,作为新的质心。
接受一组点、簇的数量k和最大迭代次数maxIterations作为参数。
随机选择初始质心。
进行迭代,每次迭代包括两个主要步骤:- 分配点到最近的质心:对于每个点,计算其到每个质心的距离,并将点分配到最近的质心所代表的簇。
- 更新质心:计算每个簇所有点的均值,作为新的质心。
-
分配点到最近的质心:对于每个点,计算其到每个质心的距离,并将点分配到最近的质心所代表的簇。
-
更新质心:计算每个簇所有点的均值,作为新的质心。
-
如果质心没有变化,或者达到最大迭代次数,则停止迭代。
main方法:创建了一个点的列表,并指定了簇的数量和最大迭代次数,然后调用kMeans方法进行聚类。
这个示例代码演示了K-means聚类的基本实现,但它没有使用K-means++算法来选择初始质心,也没有处理空簇的情况。在实际应用中,可能需要根据具体问题进行相应的优化和改进。


































- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
企鹅岛 官方正版中文版
- 4
捕鱼大世界 无限金币版
- 5
球球英雄 手游
- 6
情商天花板 2024最新版
- 7
内蒙打大a真人版
- 8
烦人的村民 手机版
- 9
跳跃之王手游
- 10
蛋仔派对 国服版本
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 球球英雄 手游
球球英雄 手游 情商天花板 2024最新版
情商天花板 2024最新版 内蒙打大a真人版
内蒙打大a真人版 烦人的村民 手机版
烦人的村民 手机版 跳跃之王手游
跳跃之王手游 蛋仔派对 国服版本
蛋仔派对 国服版本 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 挂机小铁匠游戏 122 安卓版
挂机小铁匠游戏 122 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 死神之影2游戏 0.42.0 安卓版
死神之影2游戏 0.42.0 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 灵魂潮汐手游 0.45.3 安卓版
灵魂潮汐手游 0.45.3 安卓版 旋转陀螺多人对战游戏 1.3.1 安卓版
旋转陀螺多人对战游戏 1.3.1 安卓版 地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
地铁跑酷黑白水下城魔改版本 3.9.0 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版