TiKV 源码分析之 PointGet
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
作者:来自 vivo 互联网存储研发团队-Guo Xiang
本文介绍了TiDB中最基本的PointGet算子在存储层TiKV中的执行流程。
一、背景介绍
TiDB是一款具有HTAP能力(同时支持在线事务处理与在线分析处理 )的融合型分布式数据库产品,具备水平扩容或者缩容等重要特性。TiDB 采用多副本+Multi-Raft 算法的方式将数据调度到不同的机器节点上,具备较高的可靠性和容灾能力。TiDB中的存储层TiKV组件,能够独立于TiDB作为一款分布式KV数据库使用,目前已经捐赠给CNCF并于2020年正式毕业。目前vivo公司内部的磁盘KV产品采用了开源的TiKV作为存储层实现, 目前已经在公司的不同业务产品中有深度实践。
TiKV作为一款KV数据库产品,同时提供了RawAPI和TxnAPI两套接口:
-
RawAPI仅支持最基本的针对单Key操作的Set/Get/Del及Scan语义
-
TxnAPI提供了基于ACID事务标准的接口,支持多Key写入的原子性
TxnAPI采用了分布式事务来保证多Key写入的原子性,其适用的业务场景与RawAPI相比来说更为广泛。本文后续内容将重点对PointGet在TiKV侧的执行流程进行分析,其内容涉及到storage和txn模块。阅读本文后,读者将会深入了解TiKV源码中Get流程的实现细节,包括如何处理读请求、如何进行数据定位和读取、如何实现事务隔离级别等方面,并且能够更好地理解TiKV的内部工作原理和性能优化。
二、PointGet介绍
2.1 TiDB视角中的PointGet
PointGet顾名思义即"点查", 它是TiDB中最为基本的几种算子之一,以下列举了两个常见的PointGet算子的使用场景:
-
根据主键Id查询
MySQL [test]> explain select * from user where id = 1024;
+-------------+---------+------+-------------------------------+---------------+
| id | estRows | task | access object | operator info |
+-------------+---------+------+-------------------------------+---------------+
| Point_Get_1 | 1.00 | root | table:user, index:PRIMARY(id) | |
+-------------+---------+------+-------------------------------+---------------+-
根据唯一索引查询
MySQL [test]> explain select * from users where name = "test";
+-------------+---------+------+-------------------------------+---------------+
| id | estRows | task | access object | operator info |
+-------------+---------+------+-------------------------------+---------------+
| Point_Get_1 | 1.00 | root | table:users, index:name(name) | |
+-------------+---------+------+-------------------------------+---------------+2.2 纯KV用户视角中的PointGet
部分业务没有完整地使用TiDB组件,而是使用官方提供的client-go/client-rust直接访问PD和TiKV。
Func testGet(k []byte) (error) {
txn, err := client.Begin()
if err != nil {
return err
}
v, err := txn.Get(context.TODO(), k)
if err != nil {
return err
}
fmt.Printf("value of key is: %+v", v)
return nil
}三、PointGet在TiDB中的实现
TiDB层为计算层,其主要职能为MySQL协议的实现以及SQL优化器和执行器的构建。客户端发起的所有SQL, 都会经过以下生命周期流程:
-
Lexer/Parser解析后得到AST,并转换为执行计划。
-
执行计划经过RBO/CBO后得到优化过后的执行计划。
-
基于执行计划构建执行器,其本质是不同的算子"套娃",整体构成一个树型结构。
TiDB的执行器基于"火山模型"构建,不同的操作算子具有不同的Executor实现:
type Executor interface {
base() *baSeexecutor
Open(context.Context) error
Next(ctx context.Context, req *chunk.Chunk) error
Close() error
Schema() *expression.Schema
}Executor中最为核心的是三个函数分别是Open/Next/Close,分别对应算子的初始化、迭代以及收尾逻辑。本文涉及的PointGet算子由PointGetExector实现,其核心的查询逻辑位于PointGetExector::Next()函数中。由于相关逻辑耦合了悲观事务,以及tikv/client-go中部分Percolator的实现,且不属于本文重点分析的主要内容,这里不展开描述,感兴趣的读者可以自行阅读。
四、PointGet在TiKV中的实现
4.1 PointGet接口定义
TiKV和TiDB使用gRPC进行通信,其接口契约定义采用了protobuf,我们可以在pingcap/kvproto项目中找到与PointGet相关的接口定义KvGet如下:
// Key/value store API for TiKV.
service Tikv {
// Commands using a transactional interface.
rpc KvGet(kvrpcpb.GetRequest) returns (kvrpcpb.GetResponse) {}
// ... other api definations ...
}其中入参GetRequest定义如下代码片段,我们可以看到,TiKV的点查接口除了key之外,还额外需要一个名为version的参数,即当前事务的start_ts(事务开始时间戳),这个时间戳是由TiDB在启动事务时从Pd组件申请而来。与很多数据库类似,TiKV也采用了MVCC机制,即同一个key在底层的存储中在不同时刻拥有不同的值,因此要想进行查询,除了key之外,还需要带上版本。
// A transactional get command. Lookup a value for `key` in the transaction with
// starting timestamp = `version`.
message GetRequest {
Context context = 1;
bytes key = 2;
uint64 version = 3;
}4.2 TiKV侧调用堆栈
TiKV作为gRPC的Server端,提供了KvGet接口的实现,相关调用堆栈为:
+TiKV::kv_get (grpc-poll-thread)
+future_get
+Storage::get
+Storage::snapshot (readpool-thread)
+SnapshotStore::get
+PointGetterBuilder::build
+PointGetter::get在一次KvGet调用中,函数执行流程会在grpc-poll-thread和readpool-thread中切换,其中前者为gRPC的poll thread,请求在被路由到Storage层后,会根据读写属性路由到不同的线程池中,只读语义的Get/Scan请求都会被路由到ReadPool中执行,这是一个特定用于处理只读请求的线程池。
4.3 Read through locks介绍
在分析后续逻辑之前,我们需要对Read through locks机制先做个简单介绍。TiKV使用Percoaltor模型来实现分布式事务,同时也引入了MVCC机制。然而其实现和传统的MVCC实现略有差异:TiKV的读取过程中若遇到其他事务提交时写入的Lock, 则需要等待或者尝试解锁,这会阻塞读取直到事务状态确定,一定程度上会损失并发性能。
然而在一些场景(如SecondaryLocks),在Key对应的锁仍然存在的情况下,我们已经知道相关事务的最终状态(提交或回滚)。如果我们将这些事务的最终状态与查询请求一起发送给TiKV, 那么TiKV可以根据这些事务状态来确定能否在有Lock的情况下安全读取,避免不必要的等待, 即本小节提到的Read through lock机制。
Context是所有的TiKV请求都会携带的上下文信息,为了实现Read through lock, https://GitHub.com/pingcap/kvproto/pull/833 这个PR在Context中添加了如下字段:
message Context {
// Read requests can ignore locks belonging to these transactions because either
// these transactions are rolled back or theirs commit_ts > read request's start_ts.
repeated uint64 resolved_locks = 13;
// Read request should read through locks belonging to these transactions because these
// transactions are committed and theirs commit_ts <= read request's start_ts.
repeated uint64 committed_locks = 22;
}其中resolved_locks用于记录读取时可以忽略的锁,这些锁对应的事务可能已被回滚,或者已成功提交但CommitTS大于当前的读StartTS,直接忽略这些锁也不影响快照一致性。
其中committed_locks则用于记录逻辑上已被正确提交但物理上Lock还未被清理的、且CommitTS小于当前读取使用的StartTS的事务。由于事务本质上已经被提交,因此读取时可以不需要返回等待,只需要通过Lock查询DefaultCF中的数据即可。
通过Read through lock机制,TiKV可以在一些Lock尚未被清理的情况下直接返回正确的结果,避免了客户端层面的Wait和ResolveLock,其具体实现在后续小节会涉及到。
4.4 Storage::get流程分析
下方代码块是经过精简过后的伪代码,主要标注了get流程中一些比较关键的步骤。
pub fn get(&self, mut ctx: Context, key: Key, start_ts: TimeStamp) -> impl Future<Output = ... >> {
self.read_pool.spawn_handle(async move {
// 1. 创建创建快照需要的上下文
let snap_ctx = prepare_snap_ctx(...);
// 2. 申请一个快照
let snapshot = Self::with_tls_engine(|engine| Self::snapshot(engine, snap_ctx)).await?;
// 3. 创建SnapshotStore对象并执行查询
let snap_store = SnapshotStore::new(...);
let result = snap_store.get(key);
// 4. 更新Metrics和Stats统计信息
});
}4.4.1 准备快照上下文
prepare_snap_ctx顾名思义即准备用于创建快照所需要的上下文对象,即SnapContext对象,其完整定义如下:
pub struct SnapContext<'a> {
pub pb_ctx: &'a Context,
pub read_id: Option<ThreadReadId>,
// When start_ts is None and `stale_read` is true, it means acquire a snapshot without any
// consistency guarantee.
pub start_ts: Option<TimeStamp>,
// `key_ranges` is used in replica read. It will send to
// the leader via raft "read index" to check memory locks.
pub key_ranges: Vec<KeyRange>,
// Marks that this snapshot request is allowed in the flashback state.
pub allowed_in_flashback: bool,
}
fn prepare_snap_ctx<'a>(...) -> Result<SnapContext<'a>> {
if !pb_ctx.get_stale_read() {
concurrency_manager.update_max_ts(start_ts);
}
if need_check_locks(isolation_level) {
concurrency_manager.read_key_check(...)
}
let mut snap_ctx = SnapContext {...};
if need_check_locks_in_replica_read(pb_ctx) {
snap_ctx.key_ranges = ...
}
}prepare_snap_ctx只需要创建一个SnapContext对象,但目前实现中多出了如下判断或操作,绝大部分都源于TiKV5.0中的AsyncCommit特性所需。
1.当本次读取非StaleRead时,需要将当前读取请求的start_ts与CurrencyManager中的max_ts进行比较,并将二者中的最大值更新为全局max_ts。这一操作用于保证异步提交事务计算出来的MinCommitTs不会破坏快照一致性。
2. 若当前的隔离级别是SnapshotIsolation或者RcCheckTs时, 则需要额外检查CurrencyManager中的内存锁。如果存在锁且当前start_ts大于锁中的MinCommitTs,TiKV会直接拒绝本次读取请求。其原因在于AsyncCommit事务Prewrite结束之前需要暂时阻止使用更新的start_ts发起的快照读,否则会导致正在异步提交的事务计算出的MinCommitTS无法满足快照一致性。
4.4.2 向Engine申请Snapshot
Engine是TiKV中对上层存储组件的一次抽象,所有实现了Engine Trait的具体实现都可以作为TiKV中的存储层组件。目前TiKV中已经实现了BTreeEngine/MockEngine/RocksEngine/RaftKV等多个实现。
pub trait Engine: Send + Clone + 'static {
// 获取用于查询的快照
fn async_snapshot(&mut self, ctx: SnapContext<'_>) -> Self::SnapshotRes;
// 提交写入的Mutation
fn async_write(&self,ctx: &Context,batch: WriteData,subscribed: u8, on_applied: Option<OnAppliedCb>) -> Self::WriteRes;
// 其他接口...
}Engine的接口定义中与读写相关的接口分别是async_snapshot和async_write。目前TiKV中的默认Engine实现为RaftKV,即一个基于Raftstore的实现。在RaftKV中,所有的写入都会通过Raft状态机进行propose/commit/apply流程,用户可以基于订阅机制获得这3个事件的通知从而做出不同处理,默认情况下,TiKV会在一次写入请求被RaftLeader apply成功后返回用户。而读取操作则需要遵循先行一致性读取,在早期版本中,一次读取需要通过Raft状态机进行一次ReadIndex才能进行,在新版中TiKV实现了基于租约的LeaseRead, 简化了读取流程。本次介绍的PointGet读取流程中,会涉及到使用async_snapshot获取一个Engine在当前时刻的快照,并基于快照进行读取。
TiKV按照KeyRange将Key拆分为不同的Region, 每个Region都是一个RaftGroup,且拥有独立的状态机推进运转。因此,RaftKV-Engine中async_snapshot返回的是一个名为RegionSnapshot的对象,其定义如下:
pub struct RegionSnapshot<S: Snapshot> {
snap: Arc<S>,
region: Arc<Region>,
apply_index: Arc<AtomicU64>,
pub term: Option<NonZeroU64>,
pub txn_extra_op: TxnExtraOp,
// `None` means the snapshot does not provide peer related transaction extensions.
pub txn_ext: Option<Arc<TxnExt>>,
pub bucket_meta: Option<Arc<BucketMeta>>,
}RegionSnapshot本质是对底层的KV引擎RocksDB层面的快照的封装,其逻辑视图如下:
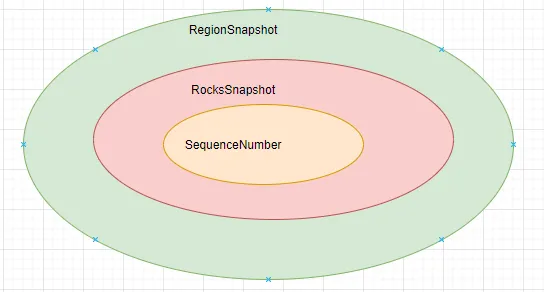
4.4.3 MVCC实现和快照隔离级别实现
前文提到的Engine::async_snapshot接口返回的快照本质是Engine在当下时刻的快照,并不等于事务层面的MVCC快照,因此在具体查询时,需要配合StartTS进行使用。TiKV中封装了一个SnapshotStore用于辅助MVCC层面的查询。其定义如下:
pub struct SnapshotStore<S: Snapshot> {
snapshot: S,
start_ts: TimeStamp,
isolation_level: IsolationLevel,
fill_cache: bool,
bypass_locks: TsSet,
access_locks: TsSet,
check_has_newer_ts_data: bool,
point_getter_cache: Option<PointGetter<S>>,
}SnapshotStore中集合了从Engine获取的快照和客户端请求附带的StartTS, 因此可以被认为是一个MVCC层面的快照。用户对SnapshotStore发起的点查会被委托给内部的PointGetter。
// PointGetter::get
pub fn get(&mut self, user_key: &Key) -> Result<Option<Value>> {
fail_point!("point_getter_get");
// 根据当前请求使用的隔离级别判定是否需要检查锁
if need_check_locks(self.isolation_level) {
// 如果需要检查锁且锁存在,则需要根据判定锁
if let Some(lock) = self.load_and_check_lock(user_key)? {
return self.load_data_from_lock(user_key, lock);
}
}
// Percoaltor正常读取流程:从WriteCF中找到<=start_ts中最大的commit_ts,并基于其存储的start_ts到DefaultCF中读取
self.load_data(user_key)
}在执行查询前,TiKV需要根据当前请求的隔离级别判定是否需要检查锁。
pub fn need_check_locks(iso_level: IsolationLevel) -> bool {
matches!(iso_level, IsolationLevel::Si | IsolationLevel::RcCheckTs)
}TiKV支持SnapshotIsolation/ReadCommitted/ReadCommittedCheckTs三种隔离级别,其中前两种需要检查锁。其原因在于LockCf中的锁是由于事务在2PC的第一阶段提交阶段写入的,事务的最终状态无法确定,如果不检查锁直接读取,那么可能导致快照读取被破坏。
fn load_and_check_lock(&mut self, user_key: &Key) -> Result<Option<Lock>> {
// 从LockCf查询该Key的锁信息
let lock_value = self.snapshot.get_cf(CF_LOCK, user_key)?;
if let Some(ref lock_value) = lock_value {
let lock = Lock::parse(lock_value)?;
// 如果存在锁则检查锁是否冲突
if let Err(e) = Lock::check_ts_conflict(
Cow::Borrowed(&lock),
user_key,
self.ts,
&self.bypass_locks,
self.isolation_level,
)
// ...
}其中Lock::check_ts_conflict的实现中会根据当前的事务隔离级别进行判定,不同的隔离级别的判定逻辑略有差异。由于本文篇幅有限,这里只分析我们常用的快照隔离级别的实现。
fn check_ts_conflict_si(lock: Cow<'_, Self>, key: &Key, ts: TimeStamp, bypass_locks: &TsSet ) -> Result<()> {
if lock.ts > ts
|| lock.lock_type == LockType::Lock
|| lock.lock_type == LockType::Pessimistic
{
return Ok(());
}
if lock.min_commit_ts > ts {
// Ignore lock when min_commit_ts > ts
return Ok(());
}
if bypass_locks.contains(lock.ts) {
return Ok(());
}
let raw_key = key.to_raw()?;
if ts == TimeStamp::max() && raw_key == lock.primary && !lock.use_async_commit {
// When `ts == TimeStamp::max()` (which means to get latest committed version
// for primary key), and current key is the primary key, we ignore
// this lock.
return Ok(());
}
// There is a pending lock. Client should wait or clean it.
Err(Error::from(ErrorInner::KeyIsLocked(
lock.into_owned().into_lock_info(raw_key),
)))
}
-
当lock.ts > ts时 ,当前查询请求可以直接忽略这个锁。其原因在于当前的lock是由具有更高start_ts的事务写入,因此即便这个事务后续被提交,其commit_ts一定大于当前的start_ts,其新写入的数据是不可见的,不会破坏快照一致性。
-
当lock_type==Lock时 ,也可以直接忽略这个锁突, 其原因在于LockType::Lock是由于创建索引产生,它只用于指示被锁定但不会修改数据,因此也可以直接被忽略。
-
当lock_type==Pessistics时 ,也可以直接忽略这个锁突,LockType::Pessistics是由于悲观事务执行DML时写入,并未进行到事务提交阶段,即使这个事务很快被提交,由于其commit_ts也一定大于当前读取的start_ts, 直接忽略并不会影响快照一致性。
-
当lock.min_commit_ts > ts时 ,也可以直接忽略这个锁,其原因在于它能保证这个AsyncCommit事务的最终计算出的commit_ts一定大于ts,即使这个事务会被提交,也不会破坏快照一致性。
-
当bypass_locks中包含了当前锁的start_ts时 , 也可以直接忽略这个锁。bypass_locks即前面Read through locks小节中提到了resloved_locks,这些锁虽然存在,但它们对应事务要么已经被回滚,要么使用了大于当前读取start_ts的commit_ts进行提交,无论是哪种情况都不会破坏快照一致性。
-
其他情况则需要返回KeyIsLocked错误给客户端,客户端收到这个错误后则会检查这个锁的过期时间,如果锁尚未过期则需要做wait,否则会尝试进行解锁恢复这个事务的状态。
若check_ts_conflict_si返回KeyIsLocked或其他错误后,TiKV会额外检查access_locks里是否包含该锁,如果该锁存在,则KeyIsLocked错误则会被忽略,同时锁会被直接返回,外层函数可以通过锁找到start_ts从而直接读取DefaultCF中的数据。这里的access_locks即Read through locks中的committed_locks,即已经知晓被提交的且commit_ts小于当前快照读start_ts的事务,在这种情况下,直接读取DefaultCF是一个超前但安全的操作,原因在在于一旦这个Lock被Resolve,用户通过新的commit_ts可以定位到同一个start_ts。
if let Err(e) = Lock::check_ts_conflict(Cow::Borrowed(&lock),user_key,self.ts,&self.bypass_locks,self.isolation_level) {
if self.access_locks.contains(lock.ts) {
return Ok(Some(lock));
}
Err(e.into())
}在不存在Key被锁定或冲突,且没有使用Read through locks读取后,TiKV则会进行正常的Percolator读取流程,即从WriteCF中找到<=start_ts中最大的commit_ts,并基于其存储的start_ts到DefaultCF中读取。
4.4.4 RegionSnapshot的Get实现
RegionSnapshot::get的实现相对比较简单,逻辑如下:
fn get_value_cf_opt(&self, opts: &ReadOptions, cf: &str, key: &[u8]) -> EngineResult<Option<Self::DbVector>> {
// 1. 检查查询的key是否在Region的范围内, 如果不在则直接返回错误。
check_key_in_range(key,self.region.get_id(),self.region.get_start_key(),self.region.get_end_key()).map_err(|e| EngineError::Other(box_err!(e)))?;
// 2. 基于查询的key拼接出raftstore层面的DataKey (raftstore在写入时会给用户key前添加一个前缀'z')。
let data_key = keys::data_key(key);
// 3. 使用内部的RocksSnapshot查询RocksDB获取key对应的值。
self.snap.get_value_cf_opt(opts, cf, &data_key).map_err(|e| self.handle_get_value_error(e, cf, key))
}4.4.5 RocksDB/Titan的Get实现
TiKV使用rust-rocksdb库使用FFI实现与RocksDB C-API的交互,RocksSnapshot::get会通过crocksdb_get_pinned_cf将查询接口委托给底层的RocksDB。值得注意的是,TiKV使用的并不是官方的RocksDB,而是自行维护的一个整合了Titan插件的版本。Titan是一个受WiscKey论文启发而创建的项目,其主要目的是将存入RocksDB的大Value从LSM-Tree中分离出来,存储到额外的Blob文件中,从而达到减小写放大的目的。
本小节我们着重分析一下TitanDB中一次查询的实现过程(做过大量精简):
Status TitanDBImpl::GetImpl(const ReadOptions& options,
ColumnFamilyHandle* handle, const Slice& key,
PinnableSlice* value) {
// 先查询RocksDB
s = db_impl_->GetImpl(options, key, gopts);
// 如果Key的Value不存在或者不是BlobIndex, 则直接返回
if (!s.ok() || !is_blob_index) return s;
// Value是BlobIndex,说明这是一个索引,还需要额外查询BlobStorage
BlobIndex index;
s = index.DecodeFrom(value);
assert(s.ok());
if (!s.ok()) return s;
BlobRecord record;
PinnableSlice buffer;
mutex_.Lock();
// 根据索引查询BlobStorage
auto storage = blob_file_set_->GetBlobStorage(handle->GetID()).lock();
mutex_.Unlock();
if (s.ok()) {
value->Reset();
value->PINSelf(record.value);
}
return s;
}五、总结
-
TiKV对数据存储层的职能进行了非常合理的抽象,通过Engine/Snapshot/Iterator等trait定义实现了存储层与上层的解耦。
-
TiKV在RocksDB提供的多列族原子性写入能力之上实现了Percolator模型,提供了分布式事务和MVCC等能力,并实现了AsyncCommit和1PC等改善了事务提交延迟。
-
TiKV实现了一个基于RocksDB的KV分离插件titan, 借鉴了Wisckey的思想将大Value从LSM-Tree中分离,在大Value的业务场景下能够通过降低写放大改善性能。
-
从PointGet的实现我们可以看到在使用了MVCC的情况下,查询时遇到前一事务Prewrite产生的Lock仍然需要等待Resolve, 因此在AsyncCommit开启的前提下,业务开发需要尽量避免设计事务提交后即刻发起查询的场景,此外也要尽量避免由于大事务提交延迟高影响相关的查询。
参考资料:
-
Async Commit 原理介绍
-
TiDB sig transaction design docs
-
TiDB 新特性漫谈:悲观事务
-
TiKV 源码解析系列文章(十九)read index 和 local read 情景分析
 戴夫大战僵尸 正版无广告
戴夫大战僵尸 正版无广告 全面战争模拟器 官方正版最新版
全面战争模拟器 官方正版最新版 theisle恐龙岛 官方手游正版
theisle恐龙岛 官方手游正版 东方魔导录 最新版安卓版
东方魔导录 最新版安卓版 剑网3无界 2024最新版
剑网3无界 2024最新版 蚊子模拟器 正版
蚊子模拟器 正版 仙魔上古起源
仙魔上古起源 世界征服者4 安卓汉化版
世界征服者4 安卓汉化版 云梦修真录 测试版
云梦修真录 测试版 jock studio 中文版
jock studio 中文版 旅猫梦幻空岛 免广告版
旅猫梦幻空岛 免广告版 开罗棒球物语汉化版破解下载 v1.3.8 安卓版
开罗棒球物语汉化版破解下载 v1.3.8 安卓版 天启圣源一元充值折扣版下载 v1.01.037 安卓版
天启圣源一元充值折扣版下载 v1.01.037 安卓版 快乐方块屋人生模拟器
快乐方块屋人生模拟器
- 讯飞有一个可以根据描述文本自动生成PPT的AI接口,有趣
- 解决el-upload上传多张图片报错ERR_UPLOAD_FILE_CHANGED的问题
- 从零开始写 Docker(十八)---容器网络实现(下):为容器插上”网线“
- 开源.NET绘图库OxyPlot的跨平台应用
- AlertManager解析:构建高效告警系统
- 如何优化SparkSQL的monaco-editor语言服务
- ShutdownMode枚举类型介绍与实践
- 手把手教你搭建Docker私有仓库Harbor
- 神奇海洋-每日科普问答
- 如何使用i.MXRT1xxx系列MCU外接24MHz有源晶振
- Microsoft.Extensions.DependencyInjection.AutoActivation扩展库介绍
- RSA算法中为什么需要两个素数?




















- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
企鹅岛 官方正版中文版
- 4
捕鱼大世界 无限金币版
- 5
情商天花板 2024最新版
- 6
内蒙打大a真人版
- 7
烦人的村民 手机版
- 8
球球英雄 手游
- 9
跳跃之王手游
- 10
蛋仔派对 国服版本
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 情商天花板 2024最新版
情商天花板 2024最新版 内蒙打大a真人版
内蒙打大a真人版 烦人的村民 手机版
烦人的村民 手机版 球球英雄 手游
球球英雄 手游 跳跃之王手游
跳跃之王手游 蛋仔派对 国服版本
蛋仔派对 国服版本 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 挂机小铁匠游戏 122 安卓版
挂机小铁匠游戏 122 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 死神之影2游戏 0.42.0 安卓版
死神之影2游戏 0.42.0 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 灵魂潮汐手游 0.45.3 安卓版
灵魂潮汐手游 0.45.3 安卓版 旋转陀螺多人对战游戏 1.3.1 安卓版
旋转陀螺多人对战游戏 1.3.1 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版 烤鱼大师小游戏 1.0.0 手机版
烤鱼大师小游戏 1.0.0 手机版