中国团队成功构建全球首个图文音三模态预训练模型
时间:2021-08-06 21:55:42来源:Lwgzc手游网作者:佚名我要评论 用手机看

扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
日前,中科院自动化所提出了全球首个图文音(视觉-文本-语音)三模态预训练模型“紫冬太初”,同时具备跨模态理解与跨模态生成能力,取得了预训练模型突破性进展。
多模态预训练模型被广泛认为是从限定领域的弱人工智能迈向通用人工智能的路径探索,其具有在无监督情况下自动学习不同任务,并快速迁移到不同领域数据的强大能力。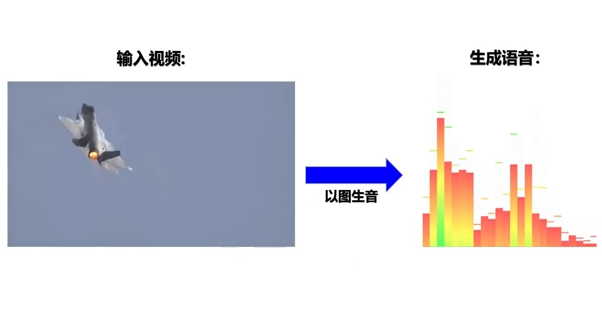
目前,已有的多模态预训练模型通常仅考虑两个模态(如图像和文本,或者视频和文本),忽视了周围环境中普遍存在的语音信息,并且模型极少兼具理解与生成能力,难以在生成任务与理解类任务中同时取得良好表现。针对这些问题,中科院自动化所此次提出的视觉-文本-语音三模态预训练模型分别采用基于词条级别、模态级别以及样本级别的多层次、多任务子监督学习框架,更关注图-文-音三模态数据之间的关联特性以及跨模态转换问题,对更广泛、更多样的下游任务提供模型基础支撑。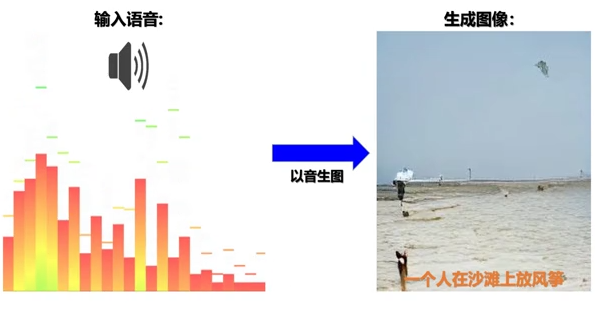
该模型不仅可实现跨模态理解(比如图像识别、语音识别等任务),也能完成跨模态生成(比如从文本生成图像、从图像生成文本、语音生成图像等任务)。 引入语音模态后的多模态预训练模型,可以突破性地直接实现三模态的统一表示,并首次实现了“以图生音”和“以音生图” 。此外,科研团队首次提出了视觉-文本-语音三模态预训练模型,实现了三模态间相互转换和生成。
中科院自动化所所长徐波介绍,三模态预训练模型的提出将改变当前单一模型对应单一任务的人工智能研发范式,三模态图文音的统一语义表达将大幅提升文本、语音、图像和视频等领域的基础任务性能,并在多模态内容的理解、搜索、推荐和问答,语音识别和合成,人机交互和无人驾驶等应用中具有重要意义。(本文来自澎湃新闻,更多原创资讯请下载“澎湃新闻”APP)
多模态预训练模型被广泛认为是从限定领域的弱人工智能迈向通用人工智能的路径探索,其具有在无监督情况下自动学习不同任务,并快速迁移到不同领域数据的强大能力。
目前,已有的多模态预训练模型通常仅考虑两个模态(如图像和文本,或者视频和文本),忽视了周围环境中普遍存在的语音信息,并且模型极少兼具理解与生成能力,难以在生成任务与理解类任务中同时取得良好表现。针对这些问题,中科院自动化所此次提出的视觉-文本-语音三模态预训练模型分别采用基于词条级别、模态级别以及样本级别的多层次、多任务子监督学习框架,更关注图-文-音三模态数据之间的关联特性以及跨模态转换问题,对更广泛、更多样的下游任务提供模型基础支撑。
该模型不仅可实现跨模态理解(比如图像识别、语音识别等任务),也能完成跨模态生成(比如从文本生成图像、从图像生成文本、语音生成图像等任务)。 引入语音模态后的多模态预训练模型,可以突破性地直接实现三模态的统一表示,并首次实现了“以图生音”和“以音生图” 。此外,科研团队首次提出了视觉-文本-语音三模态预训练模型,实现了三模态间相互转换和生成。
中科院自动化所所长徐波介绍,三模态预训练模型的提出将改变当前单一模型对应单一任务的人工智能研发范式,三模态图文音的统一语义表达将大幅提升文本、语音、图像和视频等领域的基础任务性能,并在多模态内容的理解、搜索、推荐和问答,语音识别和合成,人机交互和无人驾驶等应用中具有重要意义。(本文来自澎湃新闻,更多原创资讯请下载“澎湃新闻”APP)
热门手游下载
 天天绕圈圈游戏 1.2.5 安卓版
天天绕圈圈游戏 1.2.5 安卓版 加查海关与咖啡游戏 1.1.0 安卓版
加查海关与咖啡游戏 1.1.0 安卓版 大吉普越野驾驶游戏 1.0.4 安卓版
大吉普越野驾驶游戏 1.0.4 安卓版 沙盒星球建造游戏 1.5.0 安卓版
沙盒星球建造游戏 1.5.0 安卓版 秘堡埃德兰Elderand游戏 1.3.8 安卓版
秘堡埃德兰Elderand游戏 1.3.8 安卓版 地铁跑酷暗红双旦版 3.5.0 安卓版
地铁跑酷暗红双旦版 3.5.0 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 Robot Warfare手机版 0.4.1 安卓版
Robot Warfare手机版 0.4.1 安卓版 地铁跑酷playmods版 3.18.2 安卓版
地铁跑酷playmods版 3.18.2 安卓版 我想成为影之强者游戏 1.11.1 官方版
我想成为影之强者游戏 1.11.1 官方版 gachalife2最新版 0.92 安卓版
gachalife2最新版 0.92 安卓版 航梦游戏编辑器最新版 1.0.6.8 安卓版
航梦游戏编辑器最新版 1.0.6.8 安卓版 喵星人入侵者游戏 1.0 安卓版
喵星人入侵者游戏 1.0 安卓版 地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
相关文章
- 小度WiFi怎么安装 小度WiFi驱动安装
- Switch怎么看电池容量 电池损耗查看方法
- 5G、AI、云计算…东京奥运会背后的“黑科技”大盘点
- 专访︱年轻时存点粪?如何正确解读粪菌移植改善老年鼠认知?
- 中国社科院段伟文:AI技术价值中立,但需通过努力实现
- 中国首个原创抗体偶联药物“出海”:交易额创纪录26亿美元
- 算法新闻汇编|《人工智能担当宣言》发布,谷歌自主开发芯片
- 对话四象科技CEO:卫星如何监测自然灾害,救援痛点在哪
- 国内首个全身给药的罕见病基因疗法获批临床试验,针对血友病
- 专访|节卡机器人拿下丰田大单始末,“丰田效应”带来了什么
- “点水成金”:科学家将纯水转化为金属
- 这颗恒星为何一度突然变暗?中国科学家找到新证据
热门文章
- 1 小米手环充电没反应怎么办 小米手环无法充电解决方法
- 2 20余科学家发文称新冠病毒不可能是人为制造,专访第一作者
- 3 深圳灵明光子发布自主研发3D传感芯片,初步具备量产能力
- 4 万乘基因发布高通量单细胞测序仪,打破海外垄断国内市场现状
- 5 中国科学家提出一种新型固态原子钟方案,更适于实际应用
- 6 中国首个原创抗体偶联药物“出海”:交易额创纪录26亿美元
- 7 小米手环2闹钟怎么关闭 闹钟每隔10分钟就响一次解决方法
- 8 为何飞了这么久才到?落火之后做什么?设计师揭秘天问一号
- 9 这家上海机器人公司凭啥拿下丰田大单?背后有40年研发基因
- 10 科技部等多部门:支持女性科技人才在科技创新中发挥更大作用


热门手游推荐
换一批


















- 1
芭比公主宠物城堡游戏 1.9 安卓版
- 2
死神之影2游戏 0.42.0 安卓版
- 3
地铁跑酷忘忧10.0原神启动 安卓版
- 4
跨越奔跑大师游戏 0.1 安卓版
- 5
挂机小铁匠游戏 122 安卓版
- 6
咸鱼大翻身游戏 1.18397 安卓版
- 7
灵魂潮汐手游 0.45.3 安卓版
- 8
烤鱼大师小游戏 1.0.0 手机版
- 9
旋转陀螺多人对战游戏 1.3.1 安卓版
- 10
Escapist游戏 1.1 安卓版
 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 死神之影2游戏 0.42.0 安卓版
死神之影2游戏 0.42.0 安卓版 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 挂机小铁匠游戏 122 安卓版
挂机小铁匠游戏 122 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 灵魂潮汐手游 0.45.3 安卓版
灵魂潮汐手游 0.45.3 安卓版 烤鱼大师小游戏 1.0.0 手机版
烤鱼大师小游戏 1.0.0 手机版 旋转陀螺多人对战游戏 1.3.1 安卓版
旋转陀螺多人对战游戏 1.3.1 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版- 1
开心消消乐赚钱版下载
- 2
Minecraft我的世界基岩版正版免费下载
- 3
暴力沙盒仇恨最新版2023
- 4
疯狂扯丝袜
- 5
黑暗密语2内置作弊菜单 1.0.0 安卓版
- 6
爆笑虫子大冒险内购版
- 7
姚记捕鱼
- 8
秘密邻居中文版
- 9
班班幼儿园手机版
- 10
千炮狂鲨
 开心消消乐赚钱版下载
开心消消乐赚钱版下载 Minecraft我的世界基岩版正版免费下载
Minecraft我的世界基岩版正版免费下载 暴力沙盒仇恨最新版2023
暴力沙盒仇恨最新版2023 疯狂扯丝袜
疯狂扯丝袜 黑暗密语2内置作弊菜单 1.0.0 安卓版
黑暗密语2内置作弊菜单 1.0.0 安卓版 爆笑虫子大冒险内购版
爆笑虫子大冒险内购版 姚记捕鱼
姚记捕鱼 秘密邻居中文版
秘密邻居中文版 班班幼儿园手机版
班班幼儿园手机版 千炮狂鲨
千炮狂鲨