大语言模型中的MoE
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
1.概述
MoE代表“混合专家模型”(Mixture of Experts),这是一种架构设计,通过将不同的子模型(即专家)结合起来进行任务处理。与传统的模型相比,MoE结构能够动态地选择并激活其中一部分专家,从而显著提升模型的效率和性能。尤其在计算和参数规模上,MoE架构能够在保持较低计算开销的同时,扩展模型的能力,成为许多LLM的热门选择。
2.内容
本篇内容主要介绍MoE架构的两个核心组件:专家(Experts)和路由器(Router)。这两个组件在典型的基于LLM的架构中发挥着关键作用。专家是负责执行特定任务的子模型,而路由器则负责决定哪些专家需要在给定任务中被激活,从而优化计算效率和模型表现。
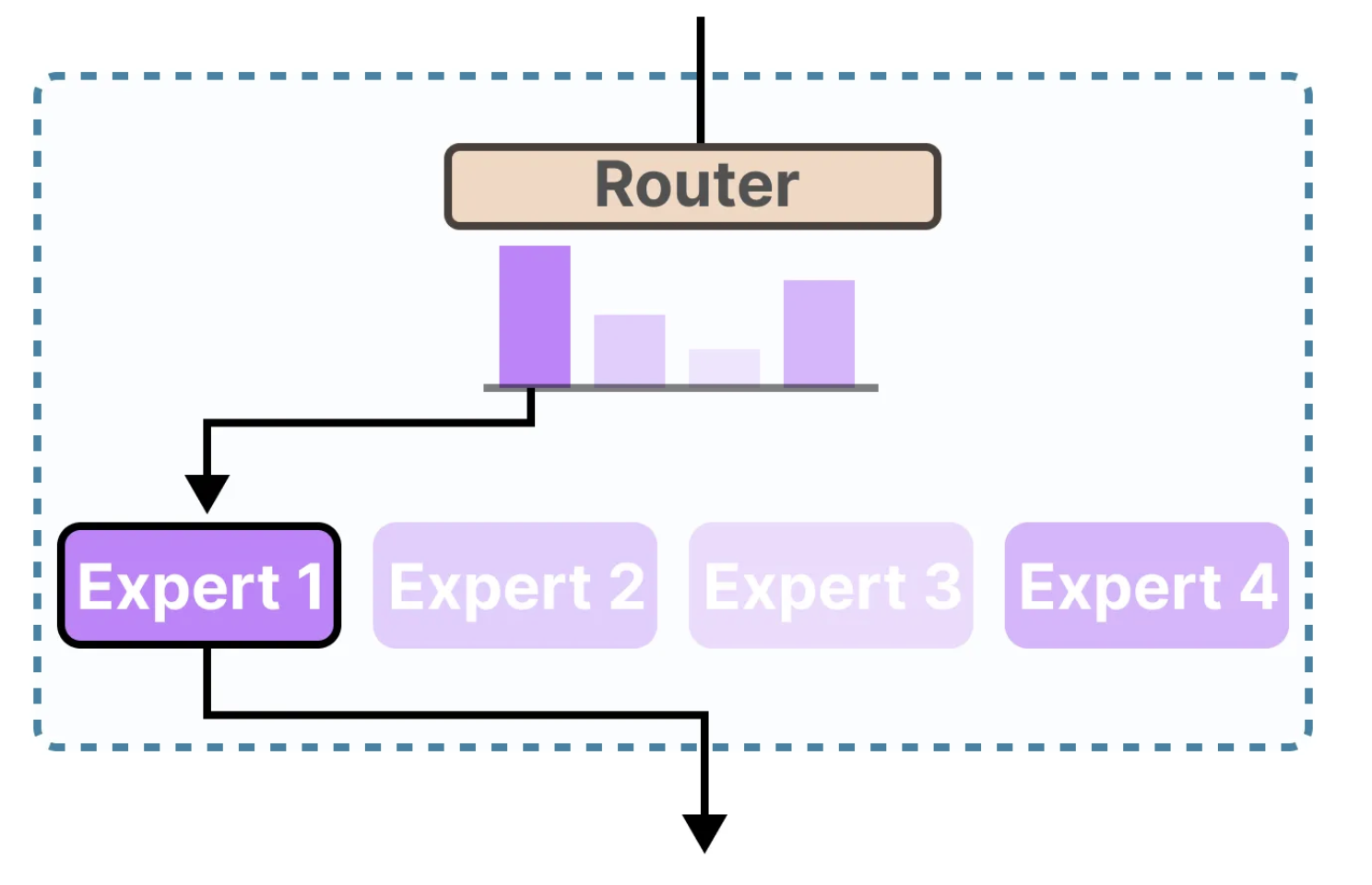
2.1 什么是专家混合
混合专家模型(MoE)是一种创新技术,通过将多个专门的子模型(即“专家”)集成进大型语言模型(LLM)中,显著提升了模型的性能和效率。
MoE架构的核心由以下两个部分构成:
- 专家(Experts) :每个前馈神经网络层都配备了一组专家,这些专家是模型中的独立子网络,每次计算时,只有一部分专家会被激活参与处理。专家通常是具备特定任务能力的神经网络。
- 路由器(Router)或门控网络(Gate Network) :该组件负责根据输入数据(如令牌)决定哪些专家会处理特定任务。路由器根据模型的输入动态地选择最适合的专家,从而提高计算效率。
通过这种结构,MoE架构不仅在保持较低计算成本的同时,能够处理更多样化、复杂的任务,也能够根据需求扩展模型规模,从而提升LLM的整体表现。
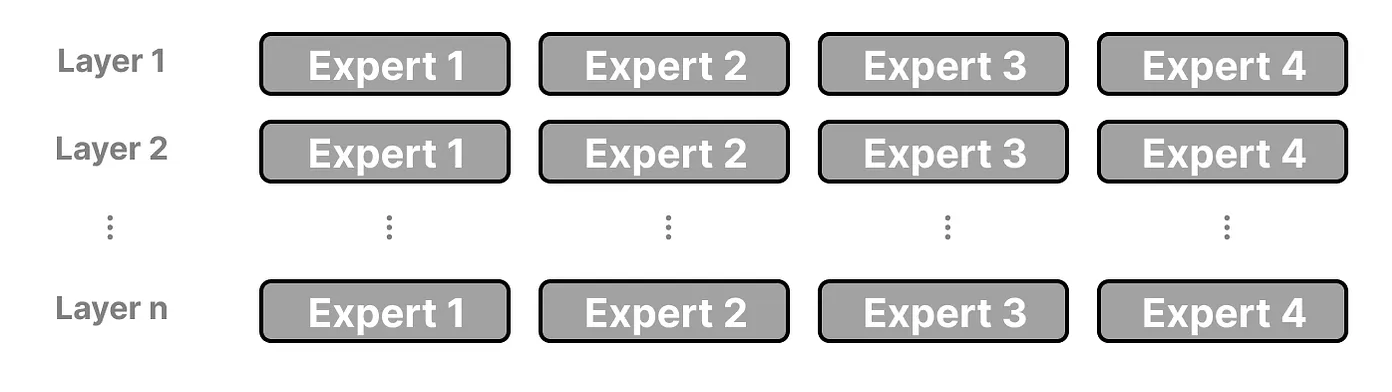
值得注意的是,MoE中的“专家”并非专注于某一特定领域,如“心理学”或“生物学”。相反,这些专家主要专注于学习词汇层面的句法结构,而不是领域知识。因此,每个专家的作用更偏向于捕捉语言的基本模式和结构,而非专业领域的深度理解。
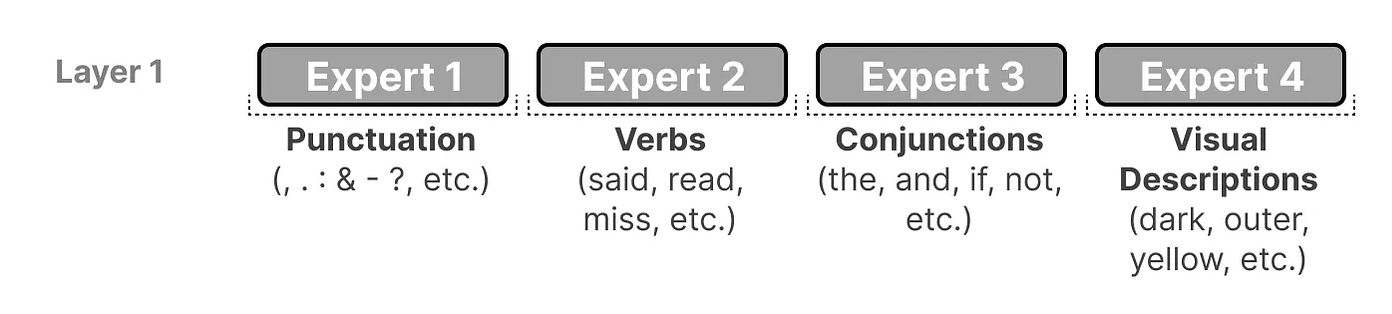
更具体地说,MoE中的“专家”专注于在特定上下文中处理特定的令牌。路由器(门控网络)根据输入数据的特征,动态选择最适合处理该数据的专家。这种机制使得模型能够根据任务需求灵活地调用不同的专家,从而提高处理效率和准确性。
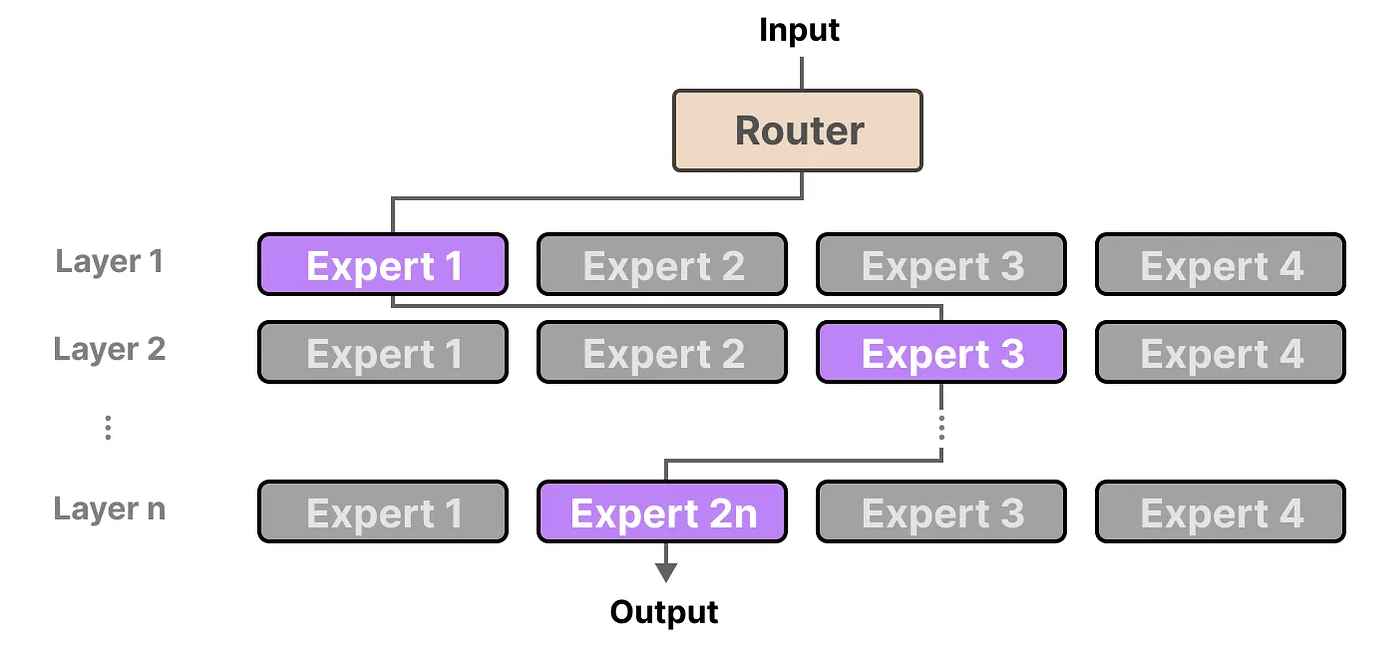
每个“专家”并不是独立的完整大型语言模型,而是嵌入在LLM架构中的一个子模型组件。它们与其他专家协同工作,共同提升整个模型的处理能力和效率。
2.2 密集层
为了更好地理解专家的作用以及它们的工作原理,我们首先需要了解MoE所替代的传统架构——密集层(Dense Layers)。
混合专家模型(MoE)构建于大型语言模型(LLM)的基本组成部分之一——前馈神经网络(FFNN)之上。需要注意的是,在标准的解码器-only Transformer架构中,FFNN通常在层归一化后被应用到每一层中。这是LLM处理信息的核心方式之一,而MoE的引入旨在通过引入多个专家模型替代传统的密集层,提升模型的表达能力和计算效率。
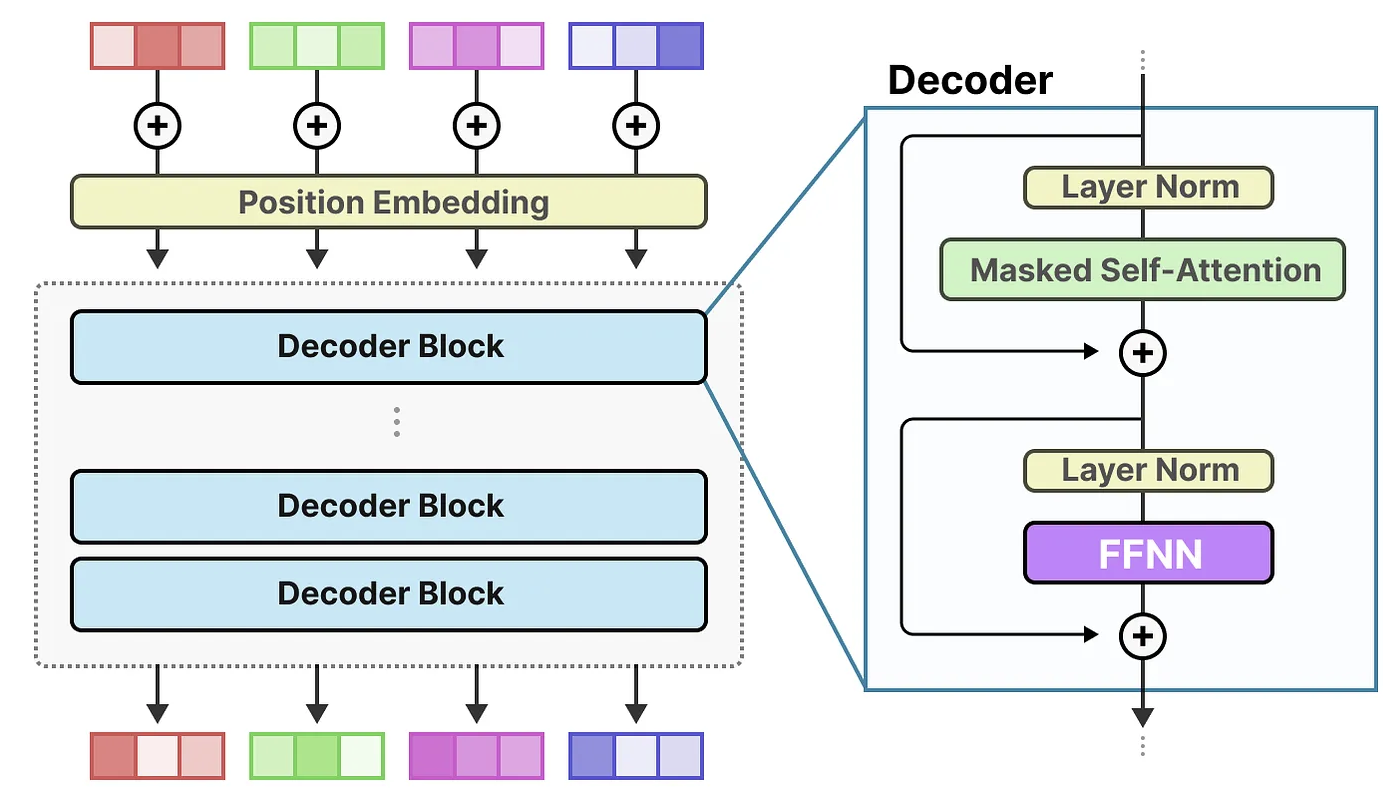
前馈神经网络(FFNN)使模型能够基于注意力机制提取的上下文信息,进一步处理并捕捉数据中的复杂关系。然而,FFNN的规模随着层数增加而迅速膨胀。为了能够学习这些复杂的关系,FFNN通常会在输入信息的基础上进行扩展,这可能导致计算开销的大幅增加。
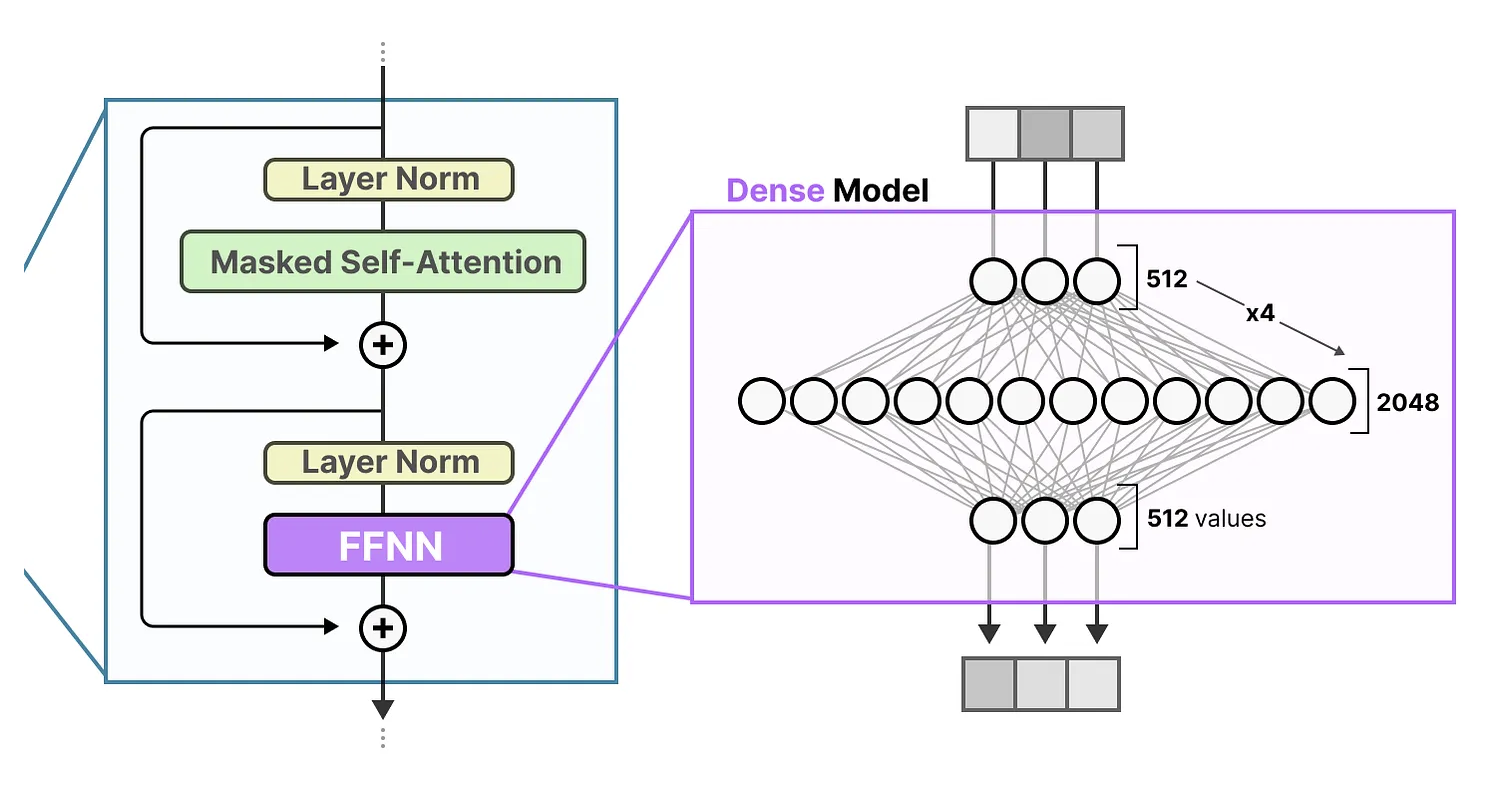
2.3 稀疏层
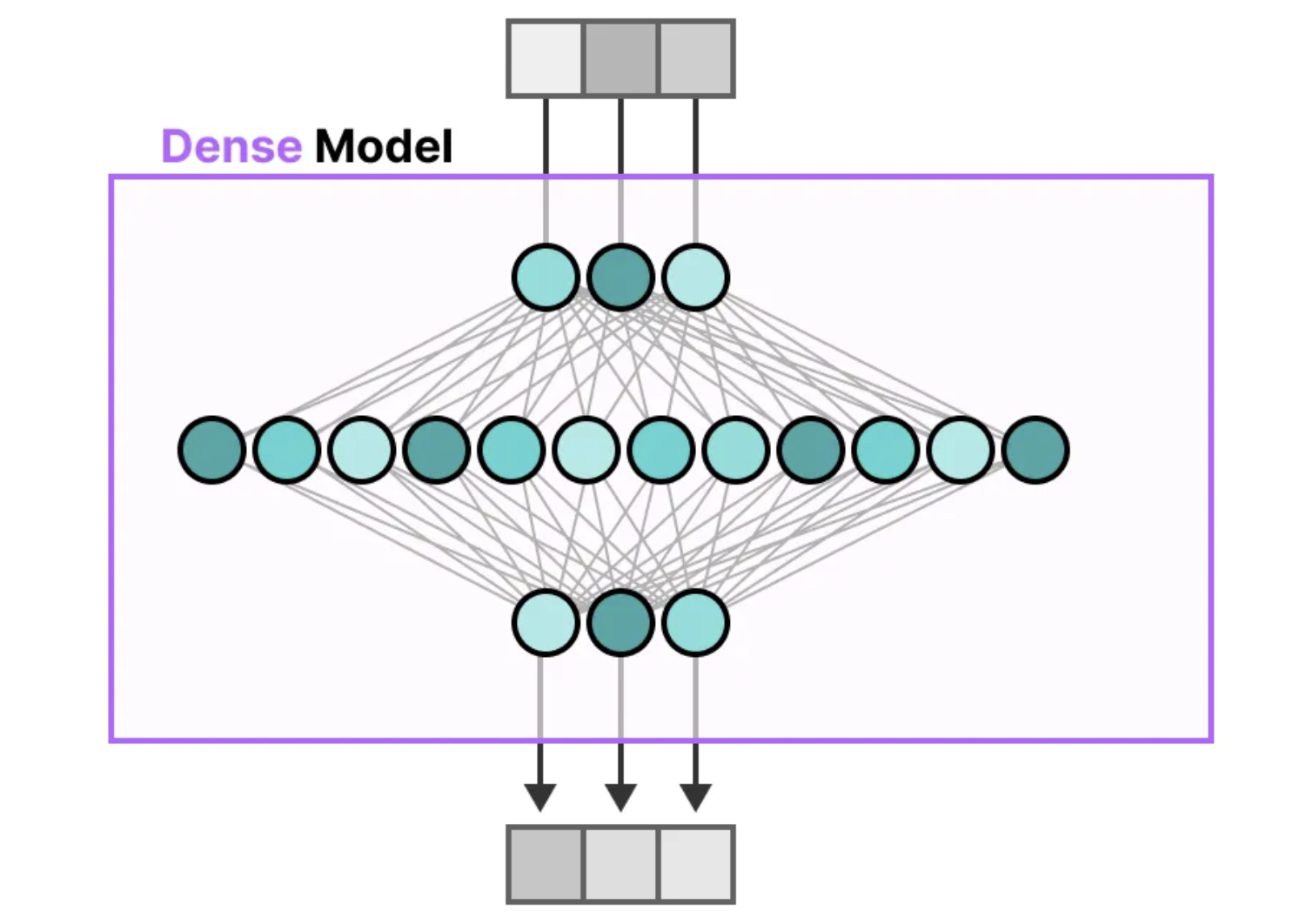
在传统的Transformer架构中,前馈神经网络(FFNN)被称为密集模型,因为它的所有参数(包括权重和偏置)都会被激活并用于计算输出,没有任何信息被忽略。仔细分析密集模型时,我们可以看到,输入信息会激活所有的参数,每个参数在计算中都会发挥作用,从而导致计算复杂度和资源消耗较大。
与密集模型不同,稀疏模型只激活一部分参数,这种方式与混合专家模型(MoE)紧密相连。具体来说,我们可以将密集模型拆分为多个“专家”子模型,重新训练它们,并在每次任务中仅激活一部分专家进行计算。这种方法不仅能减少计算开销,还能提高模型处理特定任务时的效率。
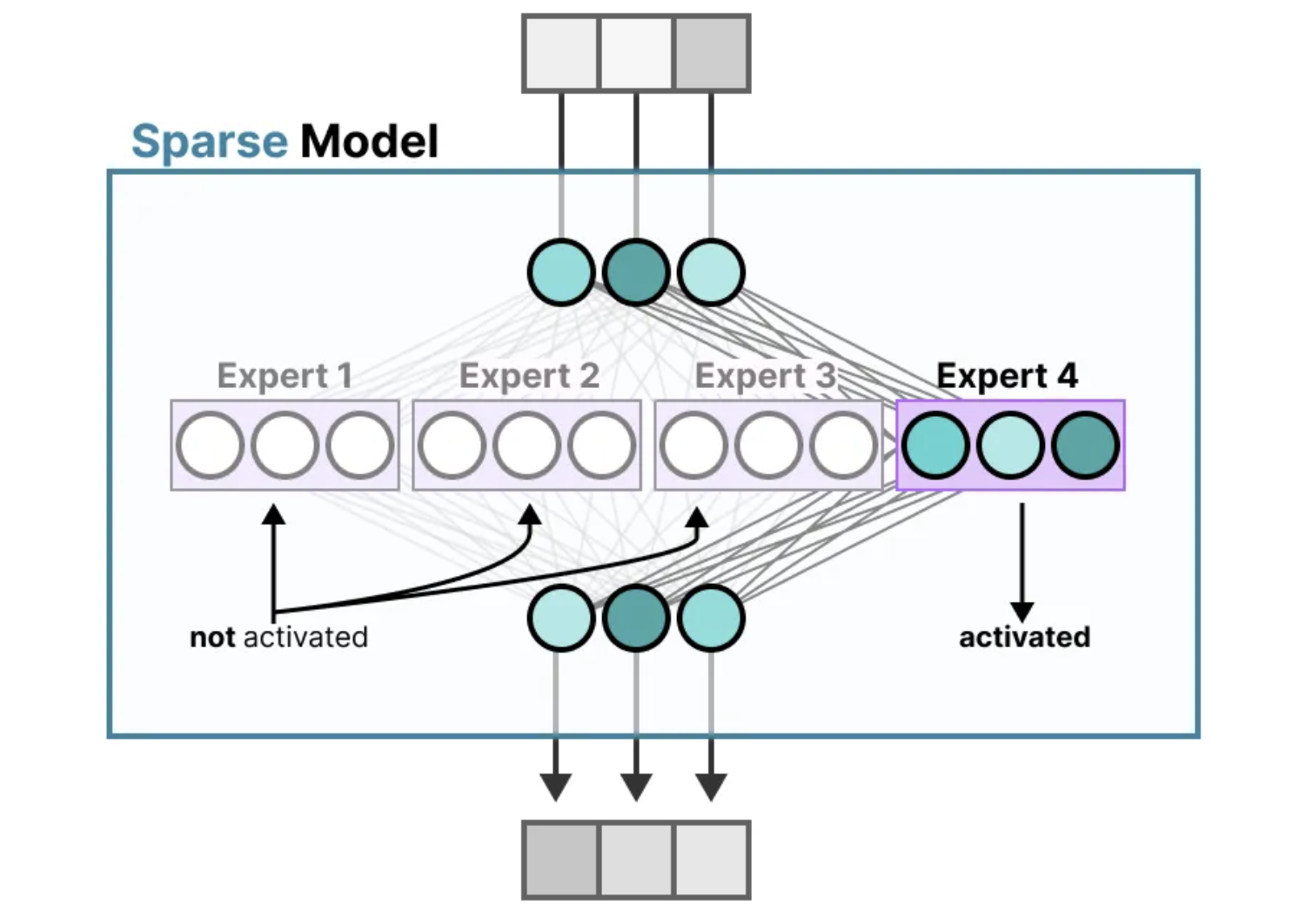
这种方法的核心理念是,每个专家在训练过程中专注于学习不同的信息。到了推理阶段,根据任务的具体需求,系统只会激活最相关的专家。这样,面对不同的问题时,我们能够选择最适合的专家来进行高效处理。
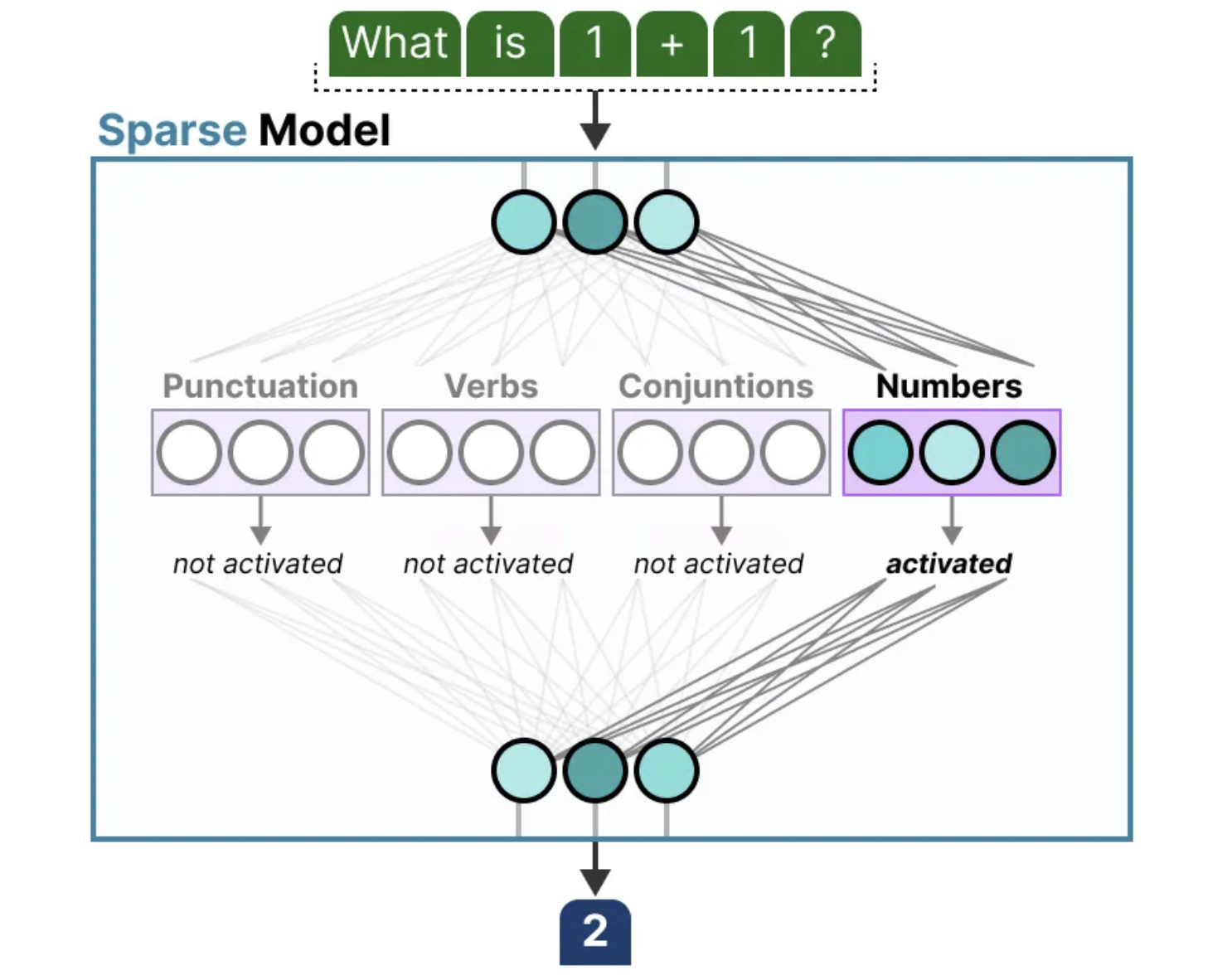
2.4 专家学习的内容
如前所述,专家并非专注于学习某一完整领域的知识,而是专注于捕捉更细粒度的信息。因此,将它们称为“专家”有时会让人误解,因为这些专家并不具备传统意义上在某一领域的深度专业知识。
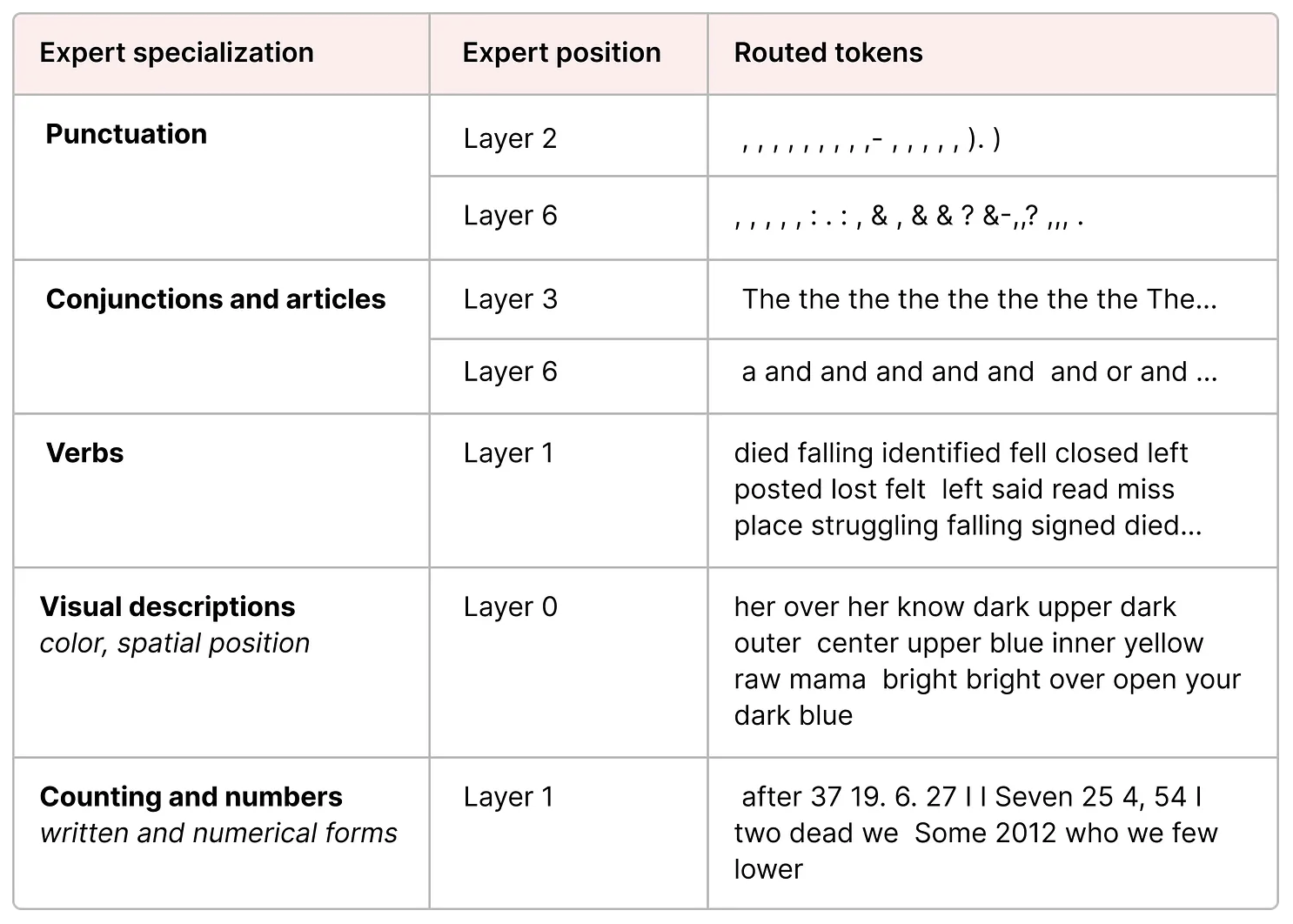
在解码器模型中,专家似乎并未表现出相同类型的专业化。尽管如此,这并不意味着所有专家在作用上是相同的。一个很好的例子可以参考《 Mixtral 8x7B 》论文,其中每个令牌都被标注为其首选专家,从而展示了专家选择的多样性和灵活性。

上图还展示了专家们更倾向于关注句法结构,而非特定领域的知识。因此,尽管解码器中的专家没有明确的专业化,它们在处理某些类型的令牌时却表现出一致性和特定的应用模式。
2.5 专家架构
虽然将专家看作是密集模型中的隐藏层并将其拆分成若干部分进行可视化是一个有趣的方式,但实际上,专家通常是独立的、完整的前馈神经网络(FFNN)。每个专家在模型中扮演着独立的角色,执行特定的计算任务。
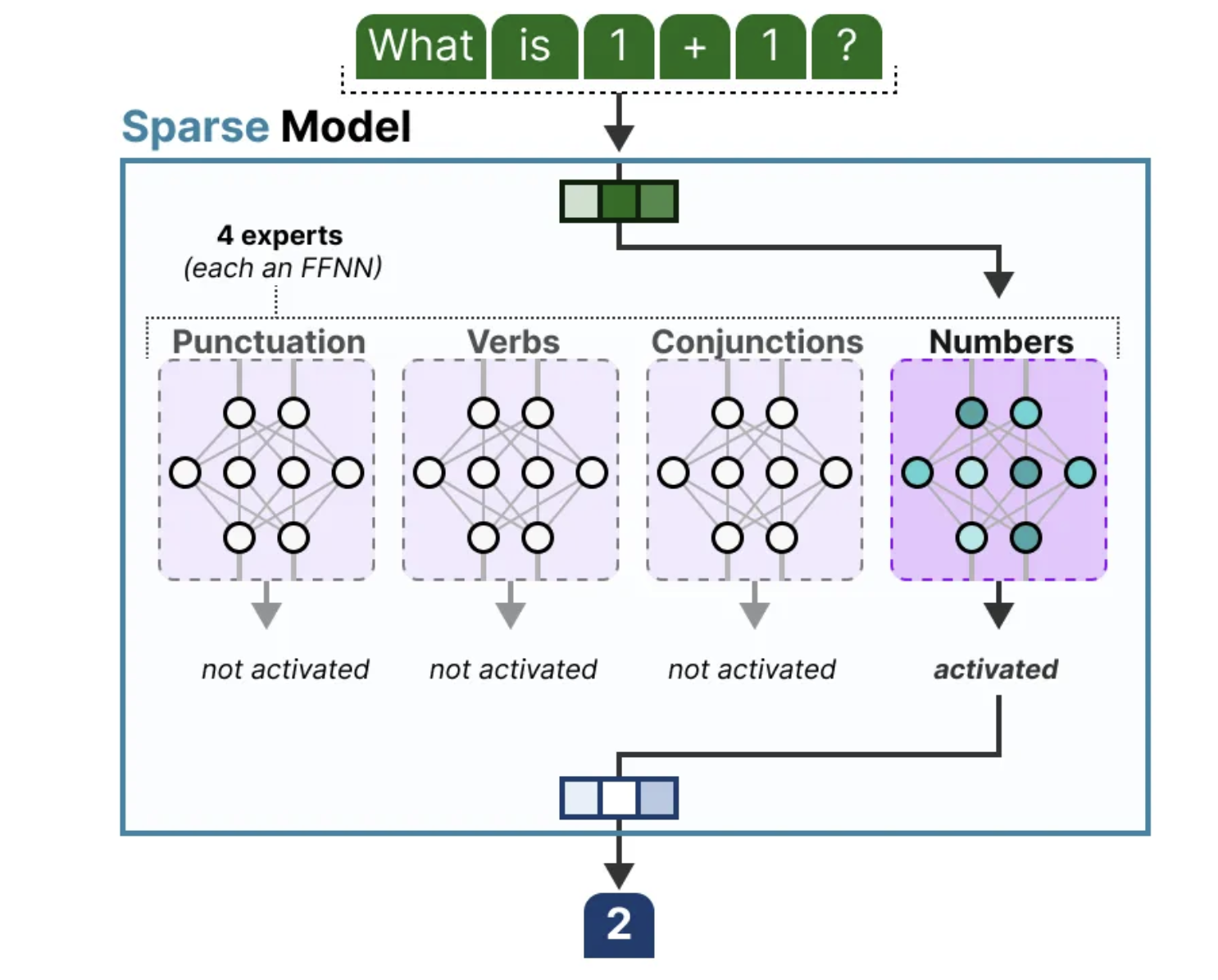
由于大多数大型语言模型(LLM)包含多个解码器层,一个输入文本通常会在生成过程中经过多个专家的处理,每个专家负责不同的任务或处理不同的特征。这样,模型可以更有效地捕捉复杂的语言模式和语境信息。
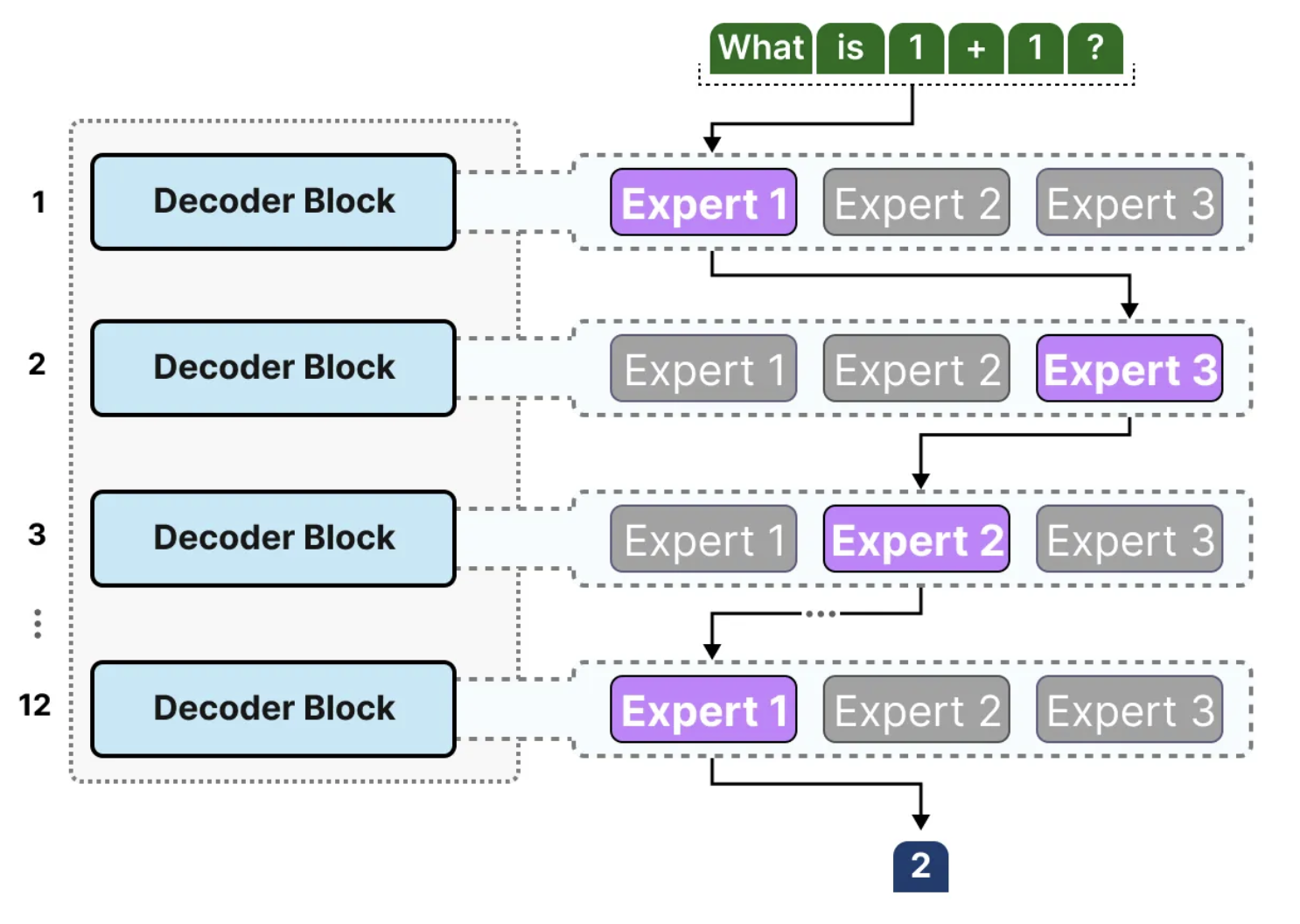
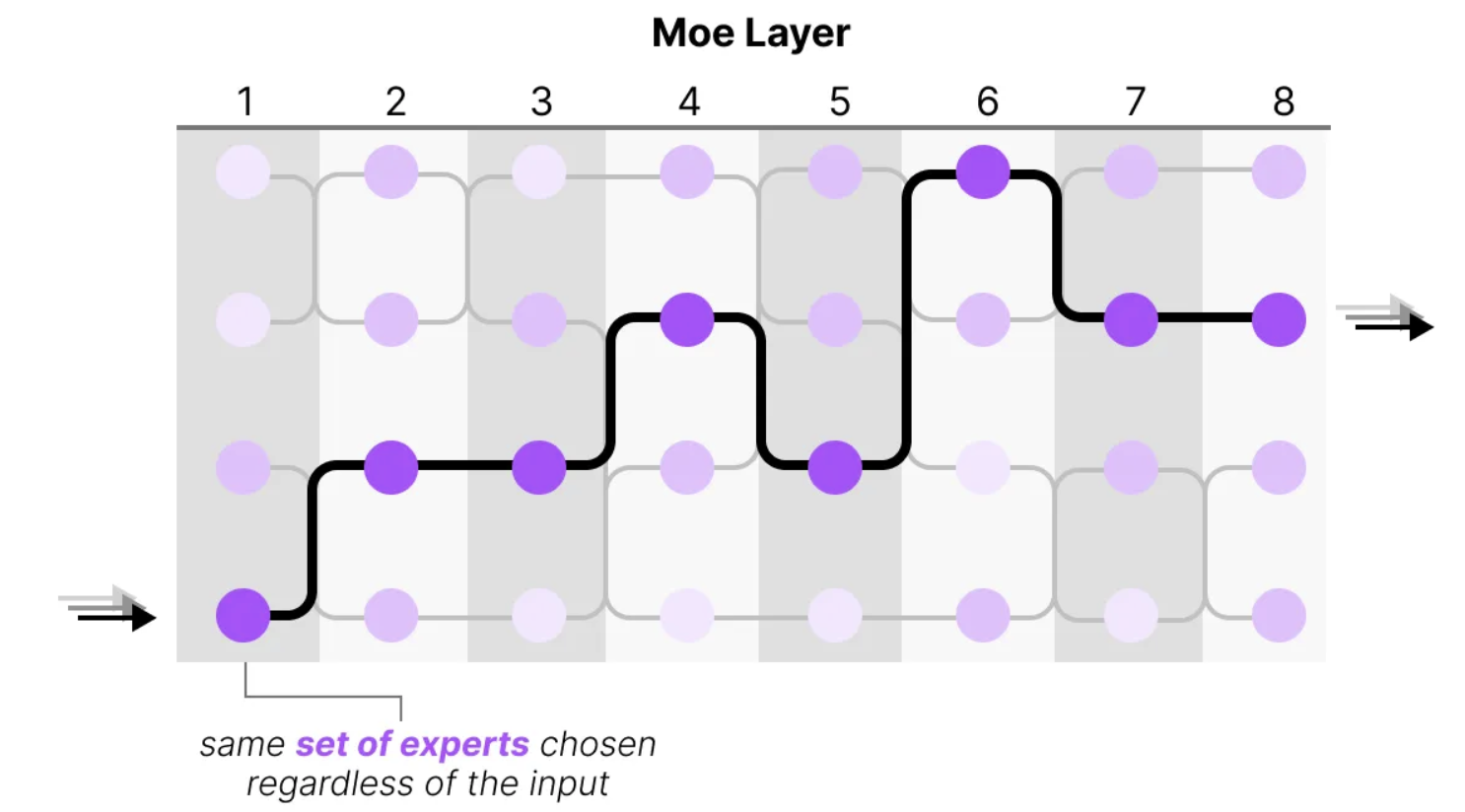
由于每个令牌可能会激活不同的专家,这导致模型在处理每个令牌时可能会选择不同的“路径”。这种动态选择使得模型能够灵活地根据不同的上下文需求进行优化。
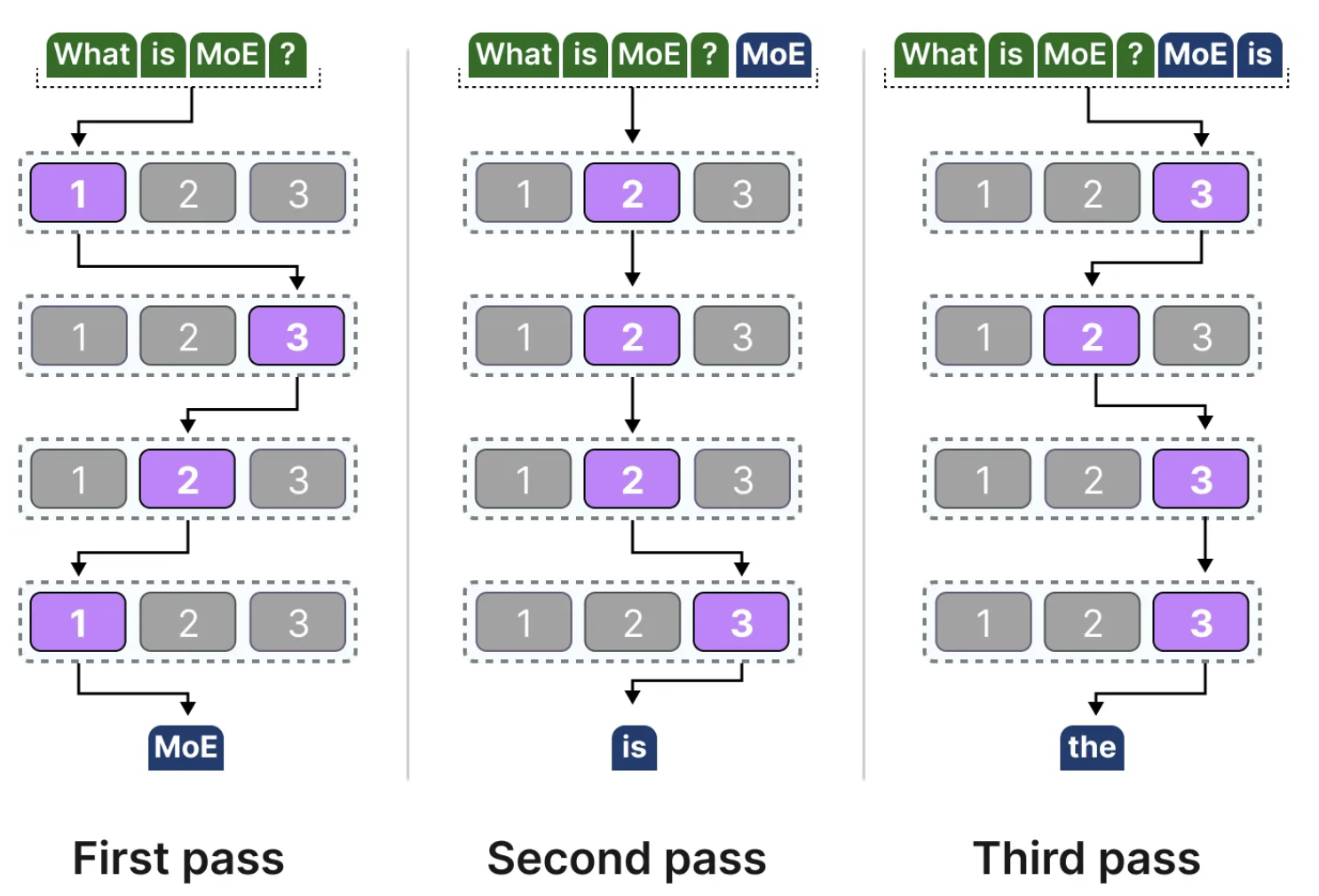
更新后的解码器模块可视化将显示更多的前馈神经网络(FFNN),每个FFNN代表一个专家。这样,每个专家都拥有独立的计算路径,以便在处理不同任务时提供更具针对性的计算能力。
3.路由
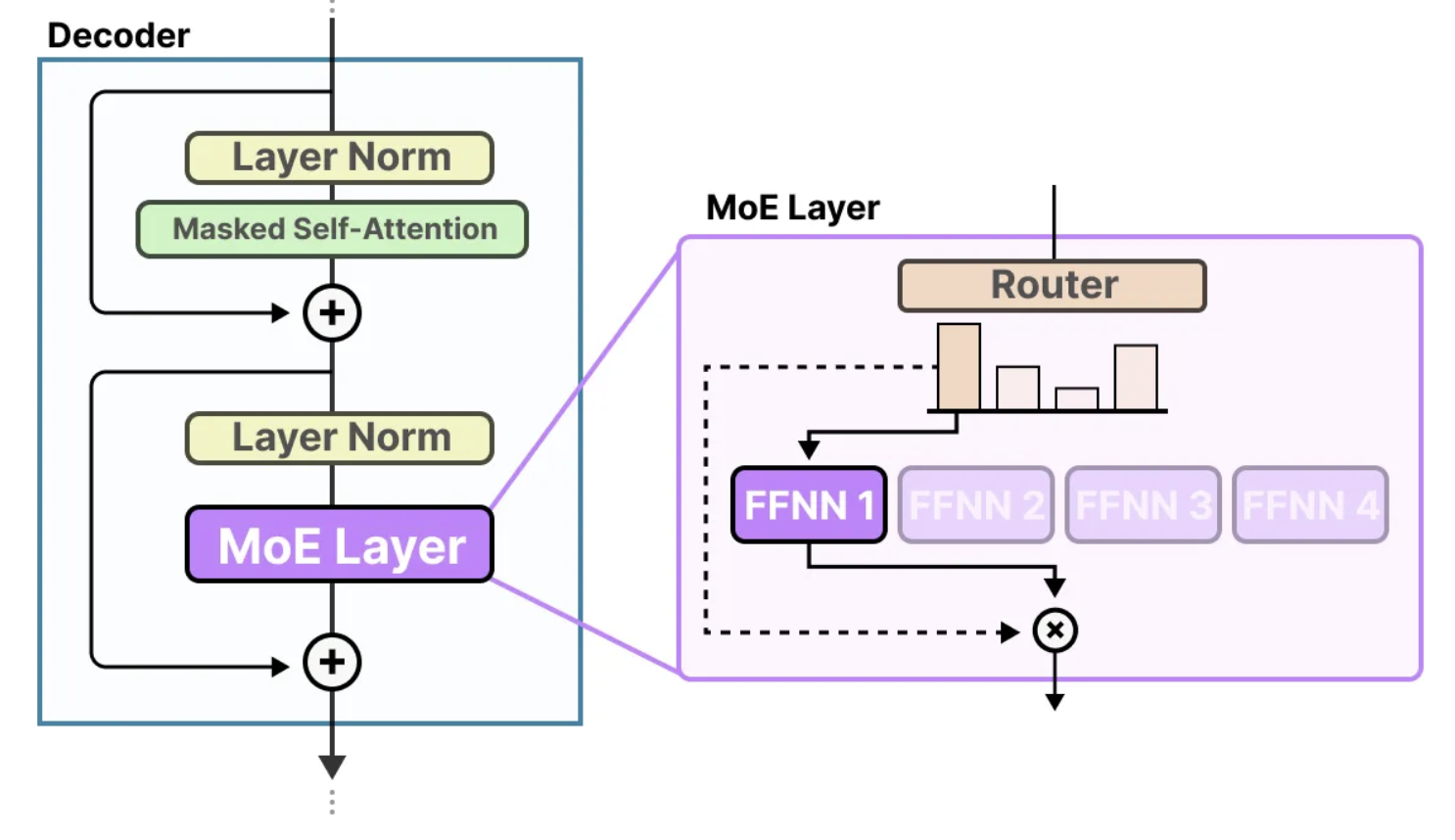
有了专家模型后,模型如何确定使用哪些专家呢?在专家之前,加入了一个路由器(或称门控网络),其作用是根据输入令牌的特征来决定激活哪个专家。路由器是一个前馈神经网络(FFNN),它会输出一组概率值,根据这些概率值来选择最适合当前任务的专家。
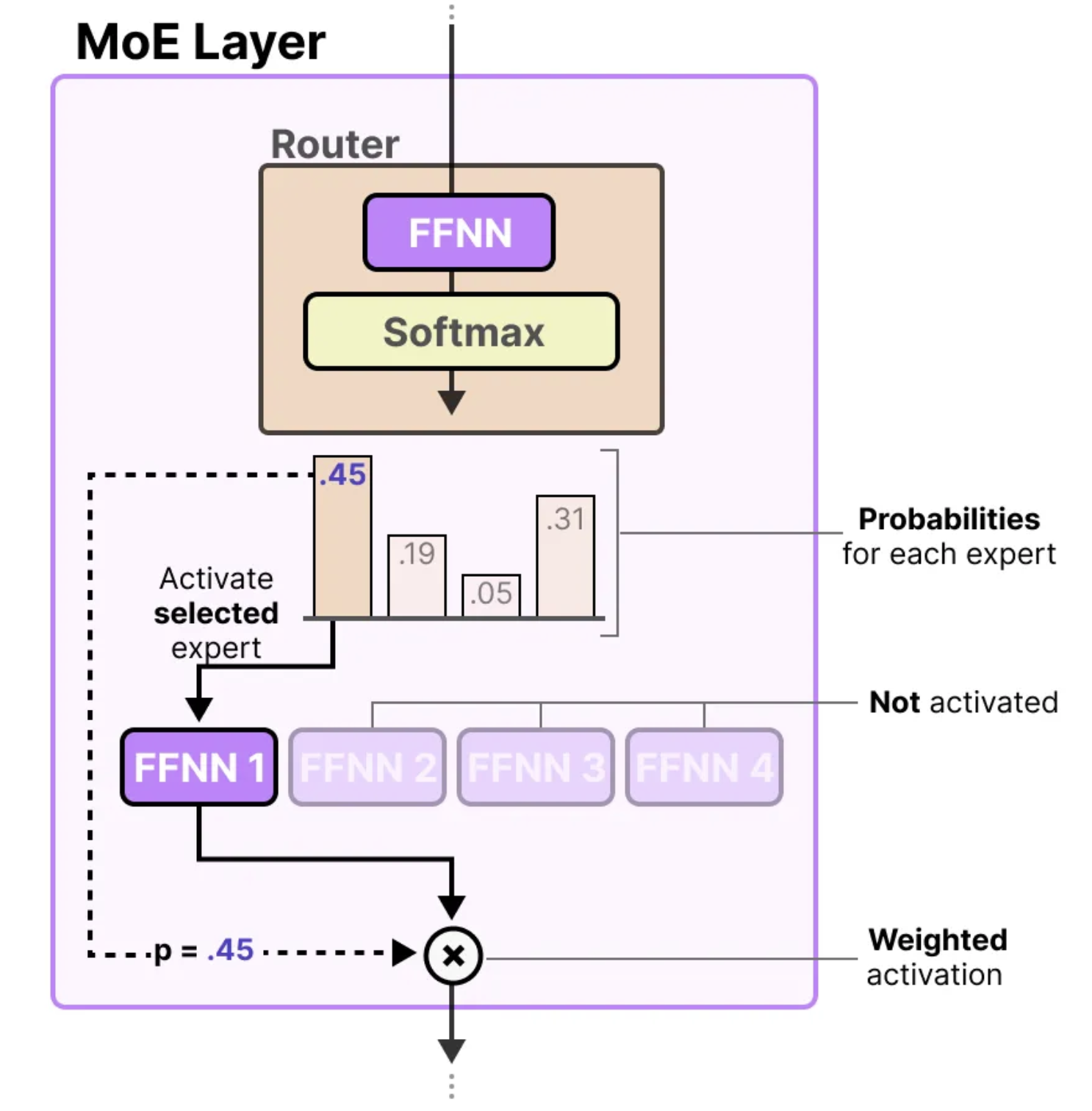
有了专家模型后,模型如何确定使用哪些专家呢?在专家之前,加入了一个路由器(或称门控网络),其作用是根据输入令牌的特征来决定激活哪个专家。路由器是一个前馈神经网络(FFNN),它会输出一组概率值,根据这些概率值来选择最适合当前任务的专家。
MoE层有两种实现方式:稀疏型和密集型混合专家模型。两者都依赖路由器来选择专家,但稀疏型MoE只激活少数几个专家,而密集型MoE则激活所有专家,只不过激活的比例和分布可能不同。这种设计使得模型在处理不同任务时可以灵活调节计算资源的分配。
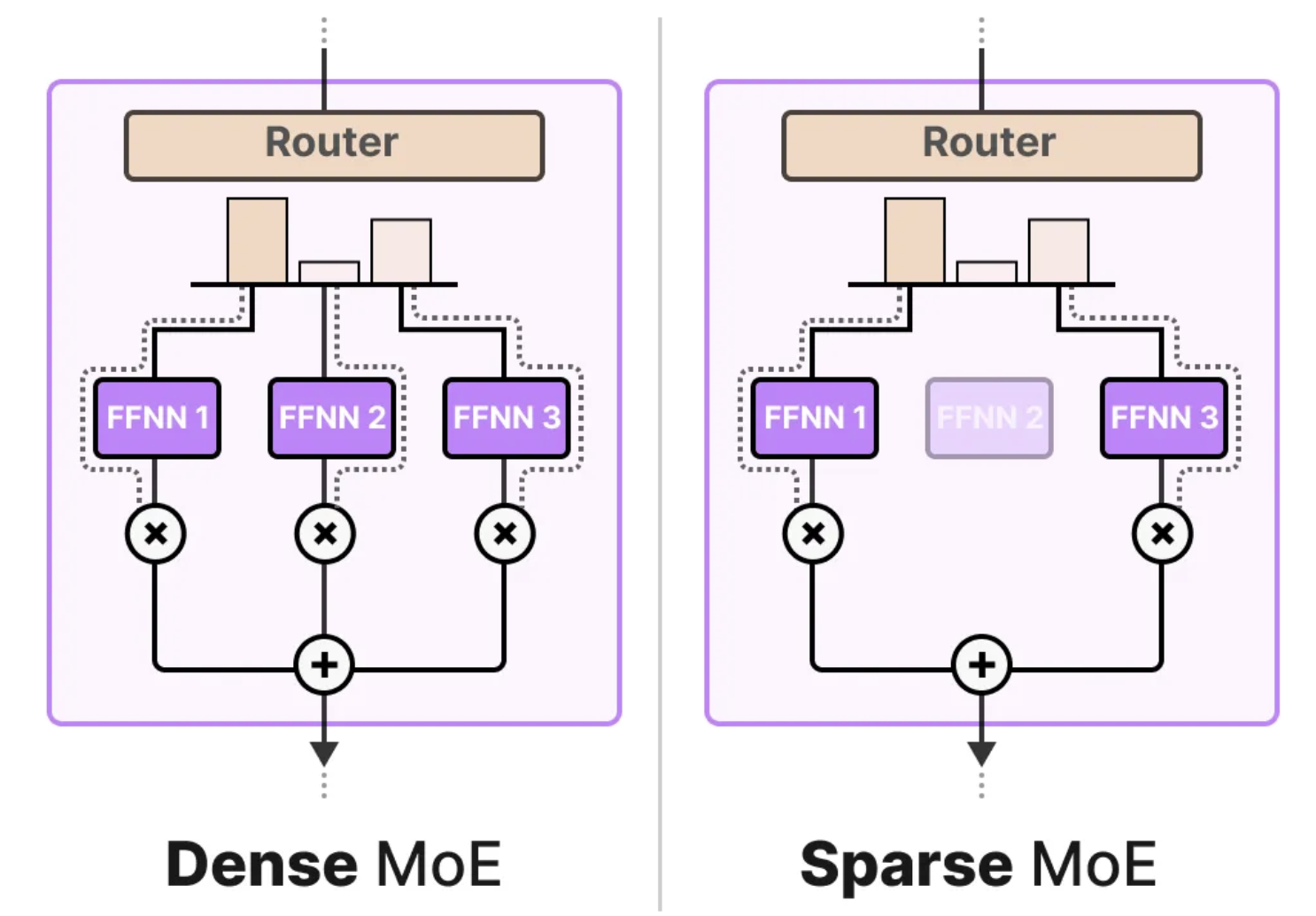
例如,给定一组令牌,普通的MoE会将令牌分配给所有专家,而稀疏型MoE则只激活少数几个专家。在现有的LLM中,提到“MoE”时,通常指的是稀疏型MoE,因为它通过仅激活一部分专家来减少计算开销,这对于大型语言模型的高效运行至关重要。
门控网络可以说是MoE中最为重要的部分,因为它不仅在推理时决定选择哪些专家,而且在训练过程中也起着关键作用。在最简单的形式下,输入(x)与路由器的权重矩阵(W)相乘,生成一个加权的输出,用于决定激活哪些专家。
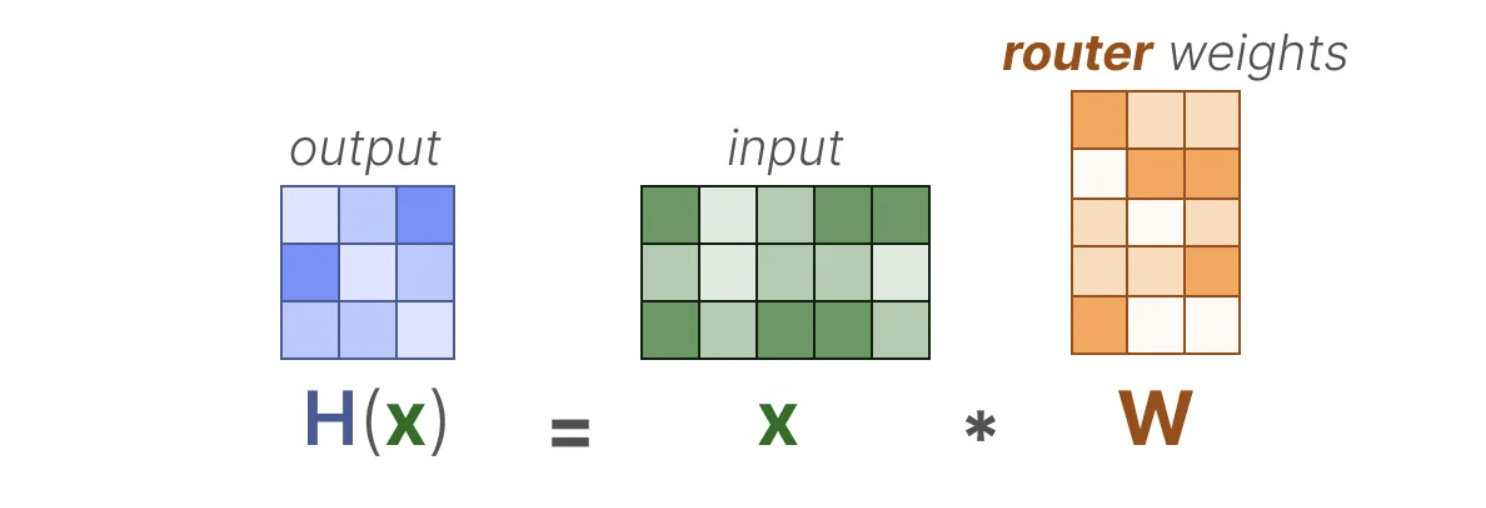
然后,我们对输出应用SoftMax函数,将其转化为每个专家的概率分布G(x)。这个概率分布决定了每个专家被选中的可能性,从而指导路由器选择最合适的专家进行处理。
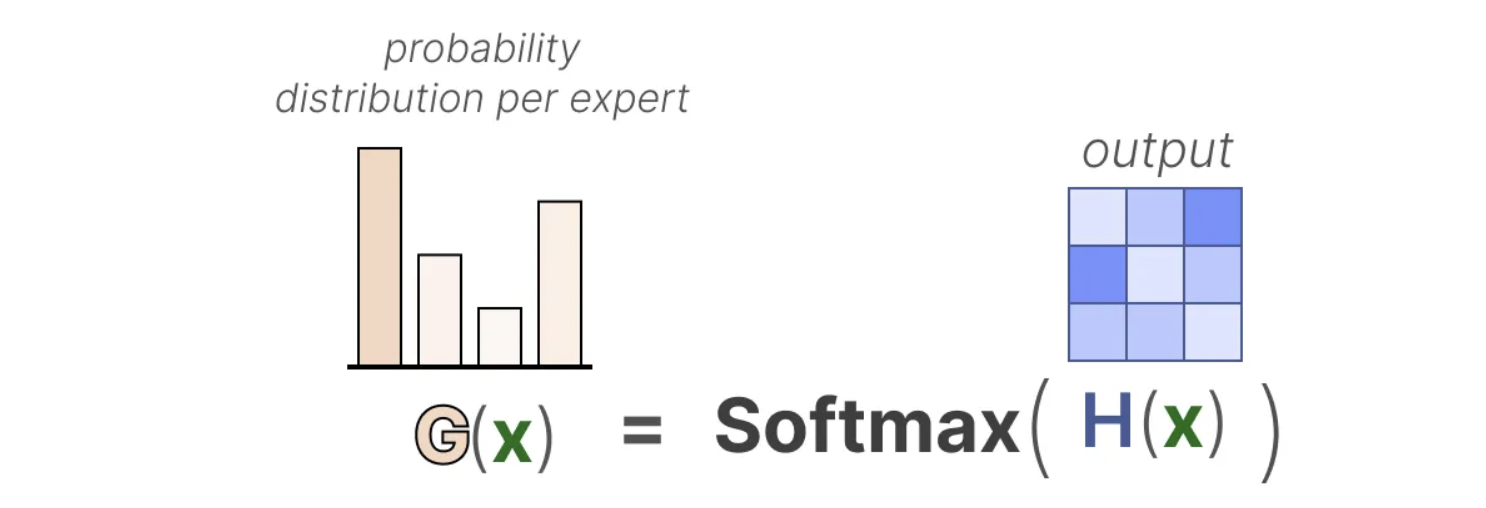
路由器根据概率分布选择最匹配的专家来处理给定的输入。最终,模型将每个选定专家的输出与相应的路由器概率相乘,并将所有结果相加,得到最终的输出。
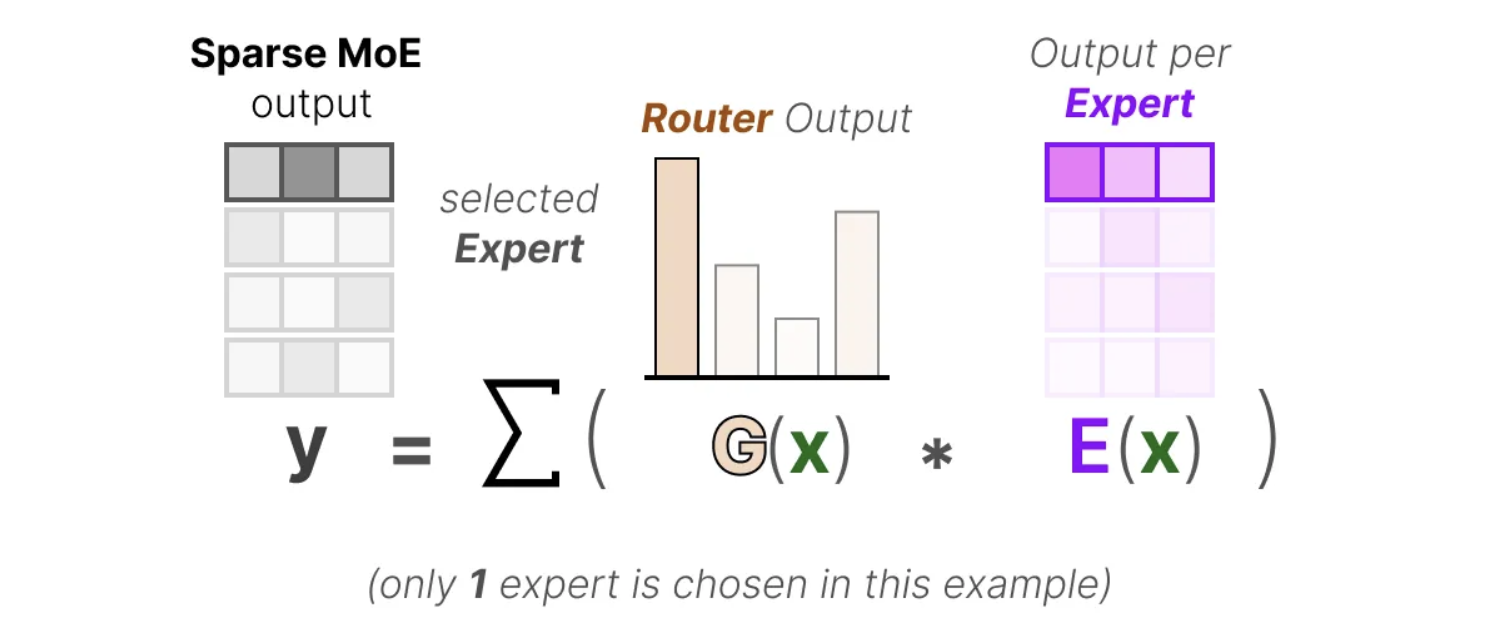
然而,这种简单的机制可能会导致路由器频繁选择相同的专家,因为某些专家的学习速度可能快于其他专家,从而使得它们在选择过程中占据主导地位。
这种不均衡的选择不仅会导致某些专家被频繁激活,而其他专家几乎没有机会参与训练,还会引发训练和推理阶段的问题。因此,我们希望在训练和推理过程中保持专家间的平衡,这就是所谓的负载均衡。负载均衡有助于避免某些专家过度拟合,提高模型的多样性和泛化能力。
4.小节
至此,我们的混合专家模型(MoE)之旅圆满结束!希望这篇文章能帮助你更好地理解这种创新技术的潜力。如今,几乎所有的模型架构都包含了至少一种MoE变体,MoE看起来将成为未来技术中的重要组成部分。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出新书了《 深入理解Hive 》、同时已出版的《 Kafka并不难学 》和《 Hadoop大数据挖掘从入门到进阶实战 》也可以和新书配套使用,喜欢的朋友或同学, 可以 在公告栏那里点击购买链接购买博主的书 进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
 老爹煎饼店togo
老爹煎饼店togo 千粟小说
千粟小说 胡椒大厨 免费版
胡椒大厨 免费版 猫咪钓鱼
猫咪钓鱼 征唐文字传奇官方版
征唐文字传奇官方版 模拟人生畅玩版官方正版
模拟人生畅玩版官方正版 狱山专属沉默
狱山专属沉默 模拟经营汉堡店
模拟经营汉堡店 湮灭:边界线
湮灭:边界线 螺旋勇士游戏中文版
螺旋勇士游戏中文版 龙岛异兽 中文版
龙岛异兽 中文版 金属战士2
金属战士2 宾果消消消 2025最新版
宾果消消消 2025最新版 时光影音修复馆
时光影音修复馆
- 使用Ollama和Open-webui部署机器硬件情况
- WiFi基础(八):WiFi安全、认证与加密
- 如何从网络包中获取TLS信息
- 如何正确命名后端字段以避免序列化问题
- 深入理解操作系统线程和调度
- 返璞归真!使用 alpinejs 开发交互式 web 应用,抛弃 node_modules 和 webpack 吧!
- Python网络爬虫实践案例:爬取猫眼电影Top100信息
- 如何在2个月内准备计算机二级C语言考试
- 开源软件:推动技术创新和社会进步的重要力量
- 一文带你搞懂GaussDB数据库性能调优
- 6502 CPU译码器的原理和工作方式
- 【鸣潮,原神PC端启动器】仿二次元手游PC端游戏启动器,以鸣潮为例。




















- 1
新麻将连连看 消消乐
- 2
托卡3D版全部版中文版下载 v2.2.2 安卓版
- 3
天天酷跑3d单机游戏
- 4
怪物猎人Puzzles艾露岛
- 5
暴富渔翁
- 6
猎鱼达人VIVO版本下载 v3.7.0.0 安卓版
- 7
植物大战僵尸幼儿园版 安卓官方版
- 8
希望之村2来生
- 9
指尖捕鱼高爆九游版下载 v10.1.40.0.0 安卓版
- 10
吸油记 正版免广告
 新麻将连连看 消消乐
新麻将连连看 消消乐 托卡3D版全部版中文版下载 v2.2.2 安卓版
托卡3D版全部版中文版下载 v2.2.2 安卓版 天天酷跑3d单机游戏
天天酷跑3d单机游戏 怪物猎人Puzzles艾露岛
怪物猎人Puzzles艾露岛 暴富渔翁
暴富渔翁 猎鱼达人VIVO版本下载 v3.7.0.0 安卓版
猎鱼达人VIVO版本下载 v3.7.0.0 安卓版 植物大战僵尸幼儿园版 安卓官方版
植物大战僵尸幼儿园版 安卓官方版 希望之村2来生
希望之村2来生 指尖捕鱼高爆九游版下载 v10.1.40.0.0 安卓版
指尖捕鱼高爆九游版下载 v10.1.40.0.0 安卓版 吸油记 正版免广告
吸油记 正版免广告- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
新麻将连连看 消消乐
- 4
捕鱼大世界 无限金币版
- 5
企鹅岛 官方正版中文版
- 6
内蒙打大a真人版
- 7
跳跃之王手游
- 8
情商天花板 2024最新版
- 9
烦人的村民 手机版
- 10
球球英雄 手游
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 内蒙打大a真人版
内蒙打大a真人版 跳跃之王手游
跳跃之王手游 情商天花板 2024最新版
情商天花板 2024最新版 烦人的村民 手机版
烦人的村民 手机版 球球英雄 手游
球球英雄 手游