如何使用C#爬取动态内容网站
时间:2024-09-28 10:12:43来源:Lwgzc手游网作者:佚名我要评论 用手机看

扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
动态内容网站使用 JavaScript 脚本动态检索和渲染数据,爬取信息时需要模拟浏览器行为,否则获取到的源码基本是空的。爬取步骤如下:
使用 Selenium 获取渲染后的 HTML 文档
使用 HtmlAgilityPack 解析 HTML 文档
新建项目,安装需要的库:
Selenium.WebDriver
HtmlAgilityPack
获取 HTML 文档
需要注意的主要是以下2点:
- 设置浏览器启动参数:无头模式、禁用GPU加速、设置启动时窗口大小
- 等待页面动态加载完成:等待5秒钟,设置一个合适的时间即可
private static string GetHtml(string url)
{
ChromeOptions options = new ChromeOptions();
// 不显示浏览器
options.AddArgument("--headless");
// GPU加速可能会导致Chrome出现黑屏及CPU占用率过高
options.AddArgument("--nogpu");
// 设置chrome启动时Size大小
options.AddArgument("--window-size=10,10");
using (var driver = new ChromeDriver(options))
{
try
{
driver.Manage().Window.Minimize();
driver.Navigate().GoToUrl(url);
// 等待页面动态加载完成
Thread.Sleep(5000);
// 返回页面源码
return driver.PageSource;
}
catch (NoSuchElementException)
{
Console.WriteLine("找不到该元素");
return string.EMPty;
}
}
}
解析 HTML 文档
这里以B站为例,爬取B站UP主主页上的视频信息,如视频的标题、链接、封面。
先定义一个类来保存信息:
class VideoInfo
{
public string Title { get; set; }
public string Href { get; set; }
public string ImgUrl { get; set; }
}
定义解析函数,返回视频信息列表:
private static List<VideoInfo> GetVideoInfos(string url)
{
List<VideoInfo> videoInfos = new List<VideoInfo>();
// 加载文档
var html = GetHtml(url);
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
// 解析文档,先定位到视频列表标签
var xpath = "/html/body/div[2]/div[4]/div/div/div[1]/div[2]/div/div";
var htmlNodes = htmlDoc.DocumentNode.SelectNodes(xpath);
// 循环解析它的子节点视频信息
foreach (var node in htmlNodes)
{
var titleNode = node.SelectSingleNode("a[2]");
var imgNode = node.SelectSingleNode("a[1]/div[1]/picture/source[1]");
var title = titleNode.InnerText;
var href = titleNode.Attributes["href"].Value.Trim('/');
var imgUrl = imgNode.Attributes["srcset"].Value.Split('@')[0].Trim('/');
videoInfos.Add(new VideoInfo
{
Title = title,
Href = href,
ImgUrl = imgUrl
});
}
return videoInfos;
}
视频列表标签的 XPath 路径是通过浏览器调试工具,在指定标签上右键 复制完整的XPath 得到:
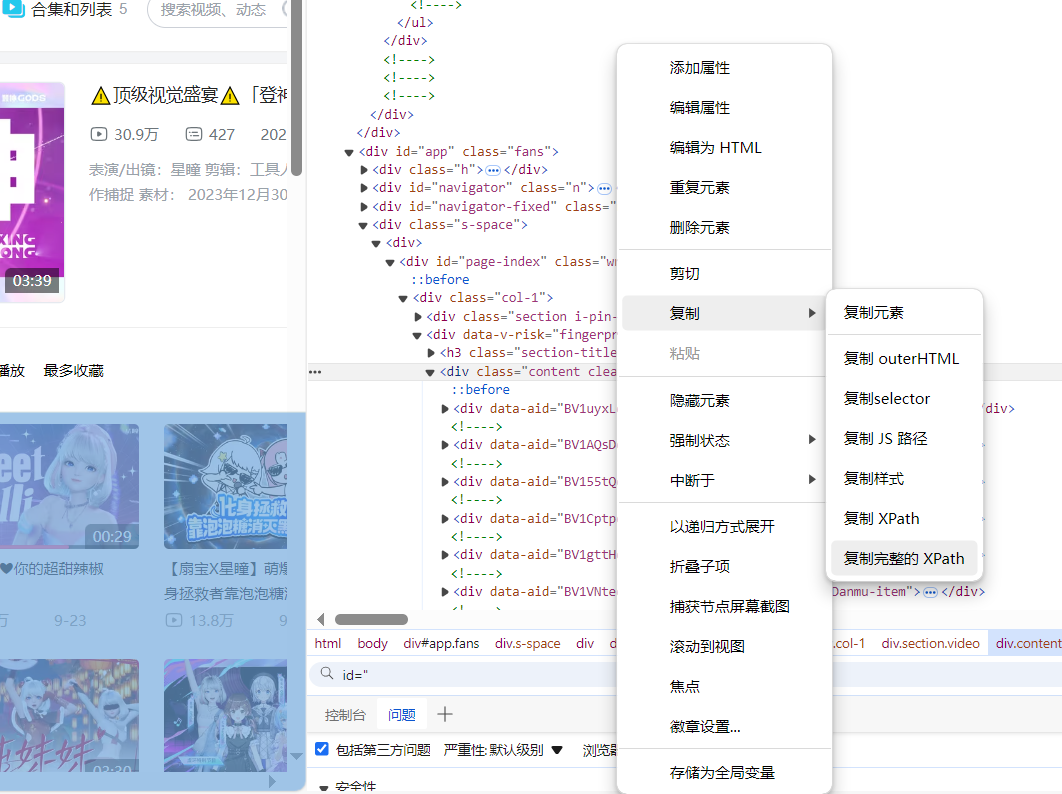
分析代码中的 node 节点时,html文本格式可能很乱,可以通过在线 HTML 代码格式化 工具格式后再进行分析。
测试
以B站UP主 星瞳_Official 为例,爬取视频信息:
static void Main(string[] args)
{
var url = @"https://space.bilibili.com/401315430";
var videoInfos = GetVideoInfos(url);
foreach (var videoInfo in videoInfos)
{
Console.WriteLine(videoInfo.Title);
Console.WriteLine(videoInfo.Href);
Console.WriteLine(videoInfo.ImgUrl);
Console.WriteLine();
}
Console.ReadKey();
}
结果如下:
等一下,好妹妹
www.bilibili.com/video/BV1uyxLeJEM9
i0.hdslb.com/bfs/archive/46a15065d1b6722a04696ffaaa2235287ceaa452.jpg
一口一个?你的超甜辣椒
www.bilibili.com/video/BV1AQsDeiEn1
i0.hdslb.com/bfs/archive/d93d47d67323ee284483e963ffed34fb9884cf61.jpg
这里只是演示爬取动态页面的方法, 如果想获取B站UP主的视频信息,建议直接使用 API 请求数据 。
参考文章
- 使用 C#语言进行网页抓取的终极指南
- C# 写个小爬虫,实现爬取js加载后的网页
- Html Agility Pack 文档
- [ 长期更新 ] C# Selenium 常用操作代码
热门手游下载
 TFT云顶之弈PBE美测服
TFT云顶之弈PBE美测服 魅影GTR 官方版
魅影GTR 官方版 西游天命人
西游天命人 秀颜
秀颜 trial xtreme极限摩托
trial xtreme极限摩托 皖政通
皖政通 小度小度
小度小度 第亿次挑战
第亿次挑战 纸飞机telegeram聊天
纸飞机telegeram聊天 钢琴之火畅玩版 1.0.172
钢琴之火畅玩版 1.0.172 阿布软件库
阿布软件库 大阪kanjo街头赛车中文版
大阪kanjo街头赛车中文版 生活日历
生活日历 Merge Match March
Merge Match March
相关文章
- .NET 开源高性能 MQTT 类库
- Visual Studio 最新WinUI工作负载和模板改进
- 华为云开发者联盟:助力开发者技术创新
- 从0到1搭建权限管理系统系列三 .net8 JWT创建Token并使用
- 比赛获奖的武林秘籍:10 一文速通“大唐杯”全国大学生新一代信息通信技术大赛
- 记一次 RabbitMQ 消费者莫名消失问题的排查
- LogViewer: 高性能实时log查看器及NLog日志输出
- 如何将VitePress公告插件分离出来并进行定制化使用
- Nuxt Kit 中的页面和路由管理
- Angular 18+ 高级教程 – 国际化 Internationalization i18n
- Unity中的三种渲染路径
- 每周C#/.NET/.NET Core技术前沿周刊精选
热门文章


热门手游推荐
换一批


















- 1
花火轮盘赌
- 2
违和感推理游戏
- 3
生物创造器 无广告
- 4
人类游乐场 安卓免费版
- 5
新麻将连连看 消消乐
- 6
筏战疯狂海战
- 7
甜瓜游乐场18.0版本下载中文
- 8
云上大陆 官服
- 9
最强细胞小小英雄最新版
- 10
米加世界娃娃屋官方版
 花火轮盘赌
花火轮盘赌 违和感推理游戏
违和感推理游戏 生物创造器 无广告
生物创造器 无广告 人类游乐场 安卓免费版
人类游乐场 安卓免费版 新麻将连连看 消消乐
新麻将连连看 消消乐 筏战疯狂海战
筏战疯狂海战 甜瓜游乐场18.0版本下载中文
甜瓜游乐场18.0版本下载中文 云上大陆 官服
云上大陆 官服 最强细胞小小英雄最新版
最强细胞小小英雄最新版 米加世界娃娃屋官方版
米加世界娃娃屋官方版 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版 地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
地铁跑酷黑白水下城魔改版本 3.9.0 安卓版 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 内蒙打大a真人版
内蒙打大a真人版