DVT:华为提出动态级联Vision Transformer,性能杠杠的 | NeurIPS 2021
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
论文主要处理Vision Transformer中的性能问题,采用推理速度不同的级联模型进行速度优化,搭配层级间的特征复用和自注意力关系复用来提升准确率。从实验结果来看,性能提升不错
来源:晓飞的算法工程笔记 公众号
论文: Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition

- 论文地址: https://arxiv.org/abs/2105.15075
- 论文代码: https://GitHub.com/blackfeather-wang/Dynamic-Vision-Transformer
Introduction
Transformers是自然语言处理 (NLP) 中占主导地位的自注意的模型,最近很多研究将其成功适配到图像识别任务。这类模型不仅在ImageNet上取得了SOTA,而且性能还能随着数据集规模的增长而不断增长。这类模型一般都先将图像拆分为固定数量的图像块,然后转换为1D token作为输入,拆分更多的token有助于提高预测的准确性,但也会带来巨额的计算成本(与token数成二次增长)。为了权衡性能和准确率,现有的这类模型都采用14x14或16x16的token数量。
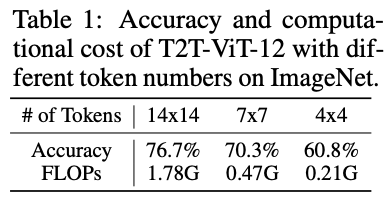
论文认为不同图片之间存在相当大的差异,使用相同数量的token处理所有图片并不是最优的。最理想的做法应为每个输入专门配置token数量,这也是模型计算效率的关键。以T2T-ViT-12为例,官方推荐的14x14 token数仅比4x4 token数增加了15.9%(76.7% 对 60.8%)的准确率,却增加了8.5倍的计算成本(1.78G 对 0.21G)。也就是说,对“简单”图片使用14x14 token数配置浪费了大量计算资源,使用4x4 token数配置就足够了。
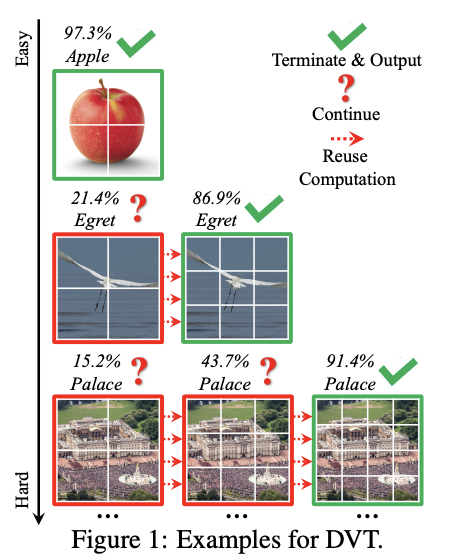
受此启发,论文提出了一种动态Vision Transformer(DVT)框架,能够根据每个图片自动配置合适的token数,实现高效计算。训练时使用逐渐增多的token数训练级联Transformer,测试时从较少的token数开始依次推理,得到置信度足够的预测即终止推理过程。通过自动调整token数,“简单”样本和“困难”样本的计算消耗将会不一样,从而显着提高效率。
另外,论文还设计了基于特征和基于关系的两种复用机制,减少冗余的计算。前者允许下游模型在先前提取的深度特征上进行训练,而后者允许利用上游模型中的自注意力关系来学习更准确的注意力图。
DVT是一个通用框架,可集成到大多数图像识别的Transformer模型中。而且可以通过简单地调整提前终止标准,在线调整整体计算成本,适用于计算资源动态波动或需要以最小功耗来实现特定性能的情况。从ImageNet和CIFAR的实验结果来看,在精度相同的情况下,DVT能将T2T-ViT的计算成本降低1.6-3.6倍,而在NVIDIA 2080Ti上的真实推理速度也与理论结果一致。
Dynamic Vision Transformer
Overview
-
Inference
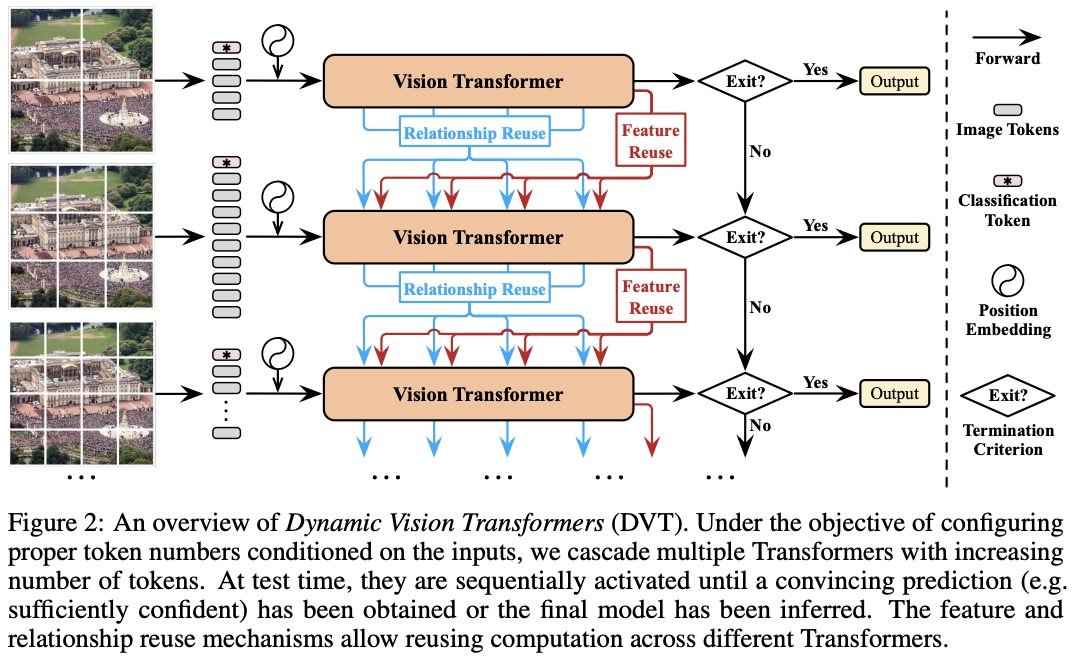
DVT的推理过程如图2所示。对于每张测试图片,先使用少量1D token序列对其进行粗略表示,可通过直接使用分割图像块或利用如tokens-to-token模块之类的技术来实现,然后通过Vision Transformer对这些token进行快速预测。由于Transformer的计算消耗与token数量成二次增长,所以这个过程很快。最后基于预设的终止标准对预测结果进行快速评估,确定是否足够可靠。
如果预测未能满足终止标准,原始输入图像将被拆分为更多token,再进行更准确、计算成本更高的推理。每个token embedding的维度保持不变,只增加token数量,从而实现更细粒度的表示。此时推理使用的Vision Transformer与上一级具有相同架构,但参数是不同的。根据设计,此阶段在某些“困难”测试图片上权衡计算量以获得更高的准确性。为了提高效率,新模型可以复用之前学习的特征和关系。在获得新的预测结果后,同样根据终止标准进行判断,不符合则继续上述过程,直到结果符合标准或已使用最终的Vision Transformer。
-
Training
训练时,需保证DVT中所有级联Vision Transformer输出正确的预测结果,其优化目标为:
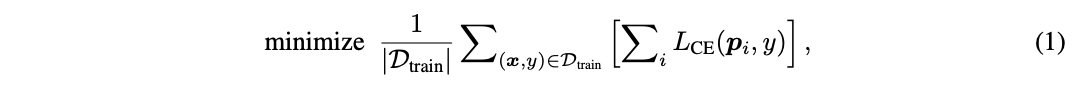
其中, \((x, y)\) 为训练集 \(D_{train}\) 中的一个样本及其对应的标签,采用标准的交叉熵损失函数 \(L_{CE}(·)\) ,而 \(p_i\) 表示第 \(i\) 个模型输出的softmax预测概率。
-
Transformer backbone
DVT是一个通用且灵活的框架,可以嵌入到大多数现有的Vision Transformer模型(如ViT、DeiT和T2T-ViT)之中,提高其性能。
Feature and Relationship Reuse
DVT的一个重要挑战是如何进行计算的复用。在使用的具有更多token的下游Vision Transformer时,直接忽略之前模型中的计算结果显然是低效的。虽然上游模型的token数量较少,但也提取了对预测有价值的信息。因此,论文提出了两种机制来复用学习到的深度特征和自注意力关系,仅增加少量的额外计算成本就能显着提高准确率。
-
Background
介绍前,先重温一下Vision Transformer的基本公式。Transformer encoder由交替堆叠的多头自注意力(MSA)和多层感知器 (MLP)块组成,每个块的之前和之后分别添加了层归一化(LN)和残差连接。定义 \(z_l\in R^{N\times D}\) 表示第 \(l\) 层的输出,其中 \(N\) 是样本的token数, \(D\) 是token的维度。需要注意的是, \(N=HW+1\) ,对应 \(H\times W\) 图像块和可学习的分类token。假设Transformer共 \(L\) 层,则整个模型的计算可表示为:
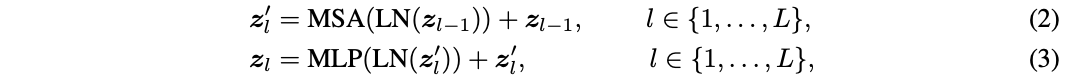
得到最终的结果 \(z_L\) 后,取其中的分类token通过LN层+全连接层进行最终预测。这里省略了position embedding的细节,论文没有对其进行修改。
-
Feature reuse
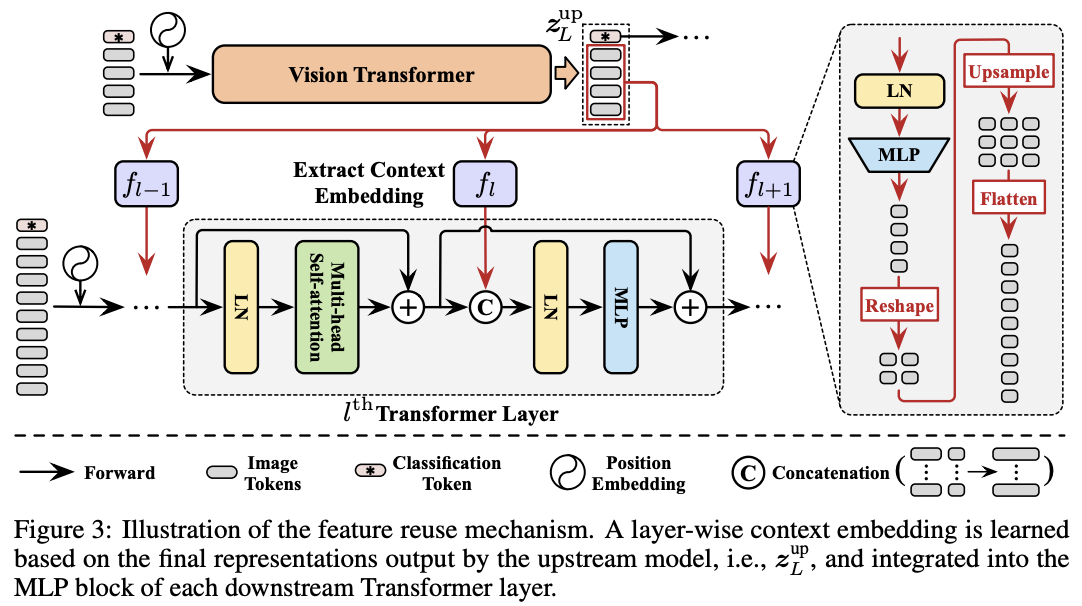
DVT中的所有Transformer都具有相同的目标,即提取关键特征进行准确识别。 因此,下游模型应该在上游模型计算的深度特征的基础上学习才是最高效的,而不是从头开始提取特征。为此,论文提出了图3的特征复用机制,利用上游Transformer最后输出的结果 \(z^{up}_L\) 来生成下游模型每层的辅助embedding输入 \(E_l\) :
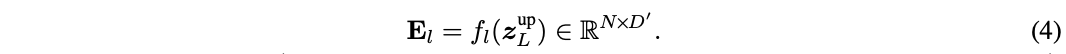
\(f_l:\mathbb{R}^{N\times D}\to \mathbb{R}^{N\times D^{'}}\) 由LN+MLP( \(\mathbb{R}^{D}\to \mathbb{R}^{D^{'}}\) )开头,对上游模型输出进行非线性转换。转换后将结果reshape到原始图像中的相应位置,然后上采样并展平来匹配下游模型的token数量。一般情况下,使用较小的 \(D^{'}\) 以便快速生成 \(f_l\) 。
之后将 \(E_l\) 拼接到下游模型对应层的中间特征作为预测的先验知识,也就是将公式3替换为:
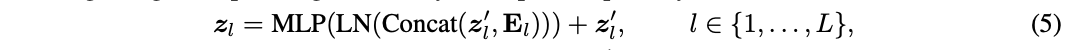
\(E_l\) 与中间特征 \(z^{'}_l\) 拼接,LN 的维度和MLP的第一层从 \(D\) 增加到 \(D+D^{'}\) 。 由于 \(E_l\) 是基于上游输出 \(z^{up}_L\) 生成的,token数少于 \(z^{'}_l\) ,它实际上为 \(z^{'}_l\) 中的每个token总结了输入图像的上下文信息。 因此,将 \(E_l\) 命名为上下文embedding。此外,论文发现不复用分类token对性能有提升,因此在公式5中将其填充零。
公式4和5允许下游模型在每层灵活地利用 \(z^{up}_L\) 内的信息,从而最小化最终识别损失,这种特征重用方式也可以认为隐式地扩大了模型深度。
-
Relationship reuse
Vision Transformer的关键在于自注意力模块能够整合整个图像的信息,从而有效地模拟图像中的长距离关系。通常情况下,模型需要在每一层学习一组注意力图来描述token之间的关系。除了上面提到的特征复用,论文认为下游模型还可以复用上游模型产生的自注意力图来进行优化。
定义输入特征 \(z_l\) ,自注意力模块先通过线性变换得到query矩阵 \(Q_l\) 、key矩阵 \(K_l\) 和value矩阵 \(V_l\) :
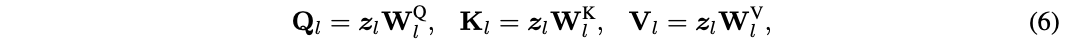
其中, \(W^Q_l\) 、 \(W^K_l\) 和 \(W^V_l\) 为权重矩阵。然后通过一个带有softmax的缩放点乘矩阵运算得到注意力图,最后根据注意力图来计算所有token的值:
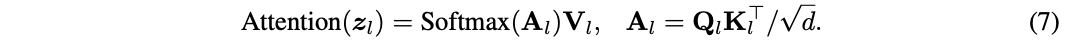
其中, \(d\) 是 \(Q\) 或 \(K\) 的点积结果维度, \(A_l\in \mathbb{R}^{N\times N}\) 为注意力图。为了清楚起见,这省略了多头注意力机制的细节,多头情况下 \(A_l\) 包含多个注意力图。
对于关系复用,先将上游模型所有层产生的注意力图(即 \(A^{up}_l, l\in \{1,\cdots , L\}\) )拼接起来:
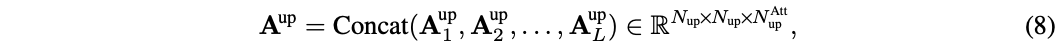
其中, \(N^{up}\) 和 \(N^{Att}_{up}\) 分别为上游模型中的toekn数和注意力图数,通常 \(N^{Att}_{up} = N^H L\) , \(N^H\) 是多头注意力的head数, \(L\) 是层数。
下游的模型同时利用自己的token和 \(A^{up}\) 来构成注意力图,也就是将公式7替换为:
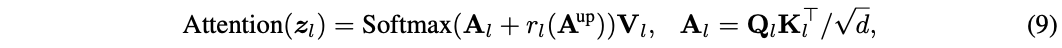
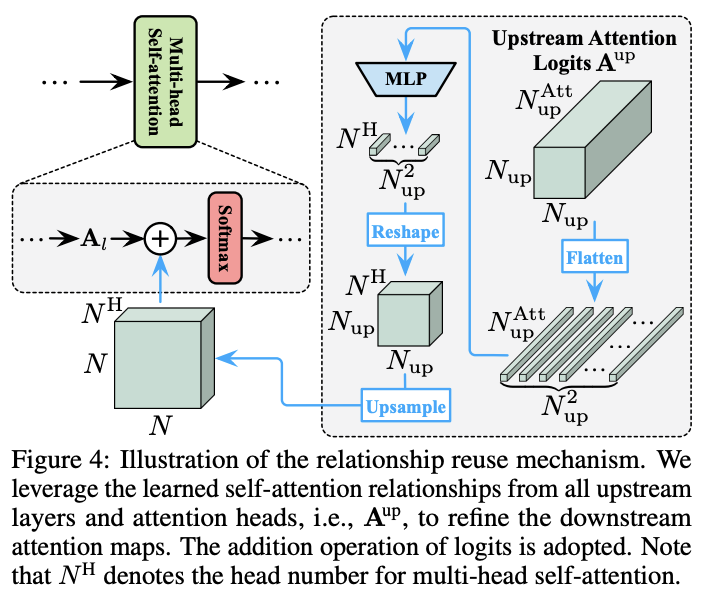
其中 \(r_l(\cdot)\) 是一个转换网络,整合 \(A^{up}\) 提供的信息来细化下游注意力图 \(A_l\) 。 \(r_l(\cdot)\) 的架构如图5所示,先进行非线性MLP转换,然后上采样匹配下游模型的注意力图大小。
公式9虽然很简单,但很灵活。有两个可以魔改的地方:
- 由于下游模型中的每个自注意力模块可以访问上游模型的所有浅层和深层的注意力头,可以尝试通过可学习的方式来对多层的注意力信息进行加权整合。
- 新生成的注意力图和复用注意力图直接相加,可以尝试通过可学习的方式来对两者加权。
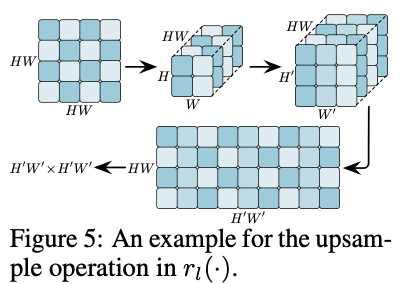
还需要注意的是, \(r_l(\cdot)\) 不能直接使用常规上采样操作。如图5所示,假设需要将 \(HW\times HW\) ( \(H =W = 2\) )的注意力图映射上采样到 \(H^{'}W^{'}\times H^{'}W^{'}\) ( \(H^{'} =W^{'} = 3\) )的大小。由于每一行对应单个token与其他 \(H\times W\) 个token的关系,直接对注意力图上采样会引入混乱的数据。因此,需要先将行reshape为 \(H\times W\) ,然后再缩放到 \(H^{'}W^{'}\times H^{'}W^{'}\) ,最后再展平为 \(H^{'}W^{'}\) 向量。
-
Adaptive Infernece
如前面所述,DVT框架逐渐增加测试样本的token数量并执行提前终止,“简单”和“困难”图像可以使用不同的token数来处理,从而提高了整体效率。对于第 \(i\) 个模型产生的softmax预测 \(p_i\) ,将 \(p_i\) 的最大项 \(max_j p_{ij}\) 与阈值 \({\mu}_{i}\) 进行比较。如果 \(max_j p_{ij}\ge {\mu}_{i}\) ,则停止并采用 \(p_i\) 作为输出。否则,将使用更多token数更多的下游模型继续预测直到最后一个模型。
阈值 \(\{\mu_1, \mu_2, \cdots\}\) 需要在验证集上求解。假设一个计算资源有限的批量数据分类场景,DVT需要在给定的计算预算 \(B > 0\) 内识别一组样本 \(D_{val}\) 。定义 \(Acc(D_{val}, \{\mu_1, \mu_2, \cdots\})\) 和 \(FLOPs(D_{val}, \{\mu_1, \mu_2, \cdots\})\) 为数据集 \(D_{val}\) 上使用阈值 \(\{\mu_1, \mu_2, \cdots\}\) 时的准确度和计算成本,最优阈值可以通过求解以下优化问题得到:
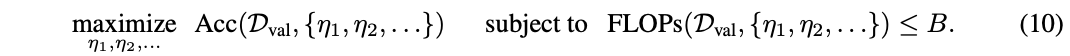
由于公式10是不可微的,论文使用遗传算法解决了这个问题。
Experiment
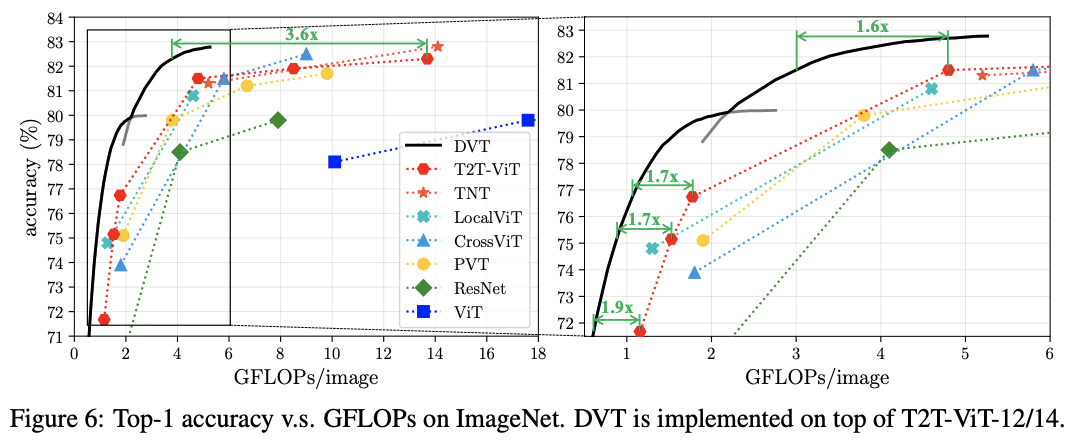
ImageNet上的性能对比。
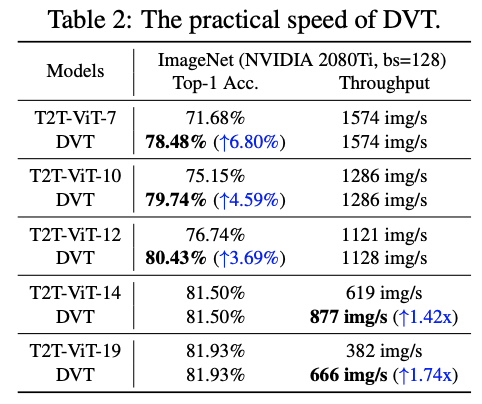
推理性能对比。
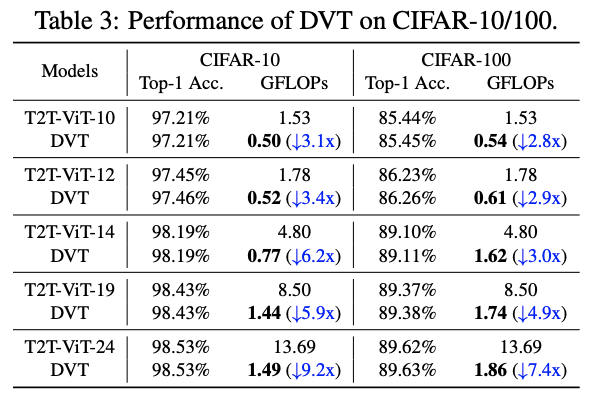
CIFAR上对比DVT在不同模型规模的性能。
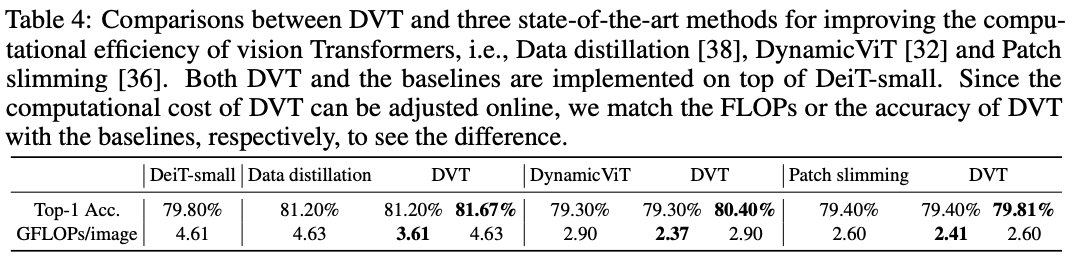
在ImageNet上与SOTA vision transformer提升方法的性能对比。
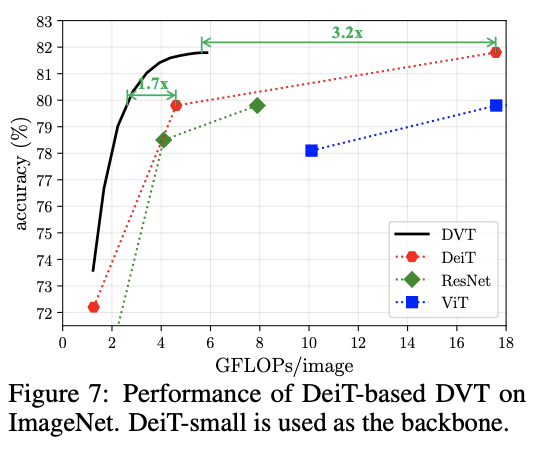
基于DeiT的DVT性能对比。
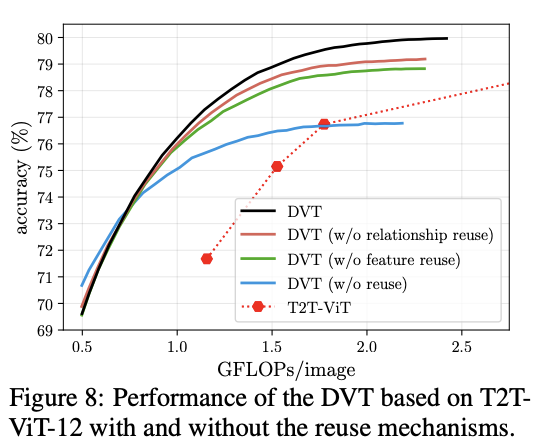
复用机制的对比实验。
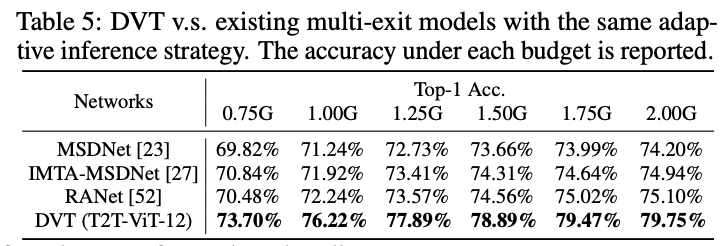
与类似的提前退出方法的性能对比。
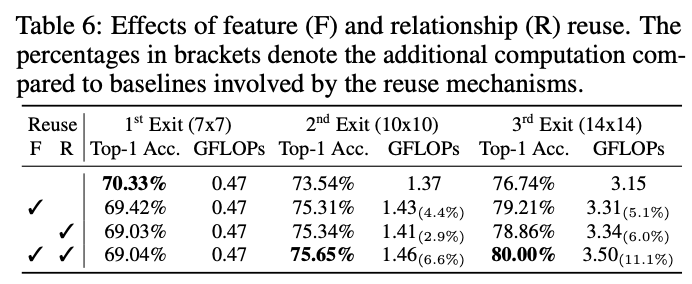
复用机制提升的性能与计算量。
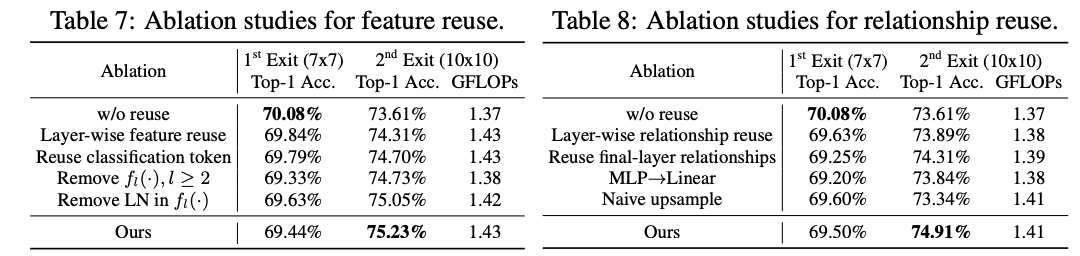
复用机制实现细节的对比实验。

难易样本的例子以及数量分布。
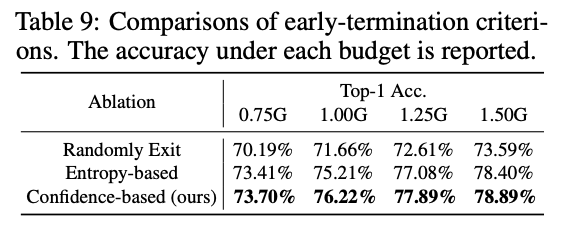
不同终止标准的性能对比。
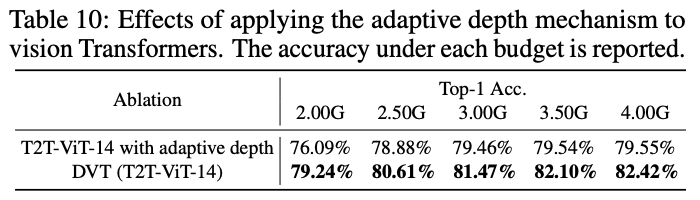
与自适应深度方法进行性能对比,自适应方法是在模型的不同位置插入分类器。
Conclusion
论文主要处理Vision Transformer中的性能问题,采用推理速度不同的级联模型进行速度优化,搭配层级间的特征复用和自注意力关系复用来提升准确率。从实验结果来看,性能提升不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

 黎明飞驰
黎明飞驰 道士修仙传说 0.1折充值仙侠
道士修仙传说 0.1折充值仙侠 明亮的光线
明亮的光线 希音
希音 空闲博主模拟器
空闲博主模拟器 末剑二免费完整版
末剑二免费完整版 啵啵鸡物语手游
啵啵鸡物语手游 末忆铁锈盒子
末忆铁锈盒子 长途旅行仿制版
长途旅行仿制版 退婚后宗主马甲藏不住免费版
退婚后宗主马甲藏不住免费版 短程极速赛车老版本
短程极速赛车老版本 扫码上号神器
扫码上号神器 1.85狂暴传奇
1.85狂暴传奇 戴夫大战僵尸 m木糖m手机版
戴夫大战僵尸 m木糖m手机版




















- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
捕鱼大世界 无限金币版
- 4
企鹅岛 官方正版中文版
- 5
内蒙打大a真人版
- 6
烦人的村民 手机版
- 7
跳跃之王手游
- 8
球球英雄 手游
- 9
情商天花板 2024最新版
- 10
旅行串串 免费下载
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 内蒙打大a真人版
内蒙打大a真人版 烦人的村民 手机版
烦人的村民 手机版 跳跃之王手游
跳跃之王手游 球球英雄 手游
球球英雄 手游 情商天花板 2024最新版
情商天花板 2024最新版 旅行串串 免费下载
旅行串串 免费下载 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 挂机小铁匠游戏 122 安卓版
挂机小铁匠游戏 122 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 死神之影2游戏 0.42.0 安卓版
死神之影2游戏 0.42.0 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版 灵魂潮汐手游 0.45.3 安卓版
灵魂潮汐手游 0.45.3 安卓版 旋转陀螺多人对战游戏 1.3.1 安卓版
旋转陀螺多人对战游戏 1.3.1 安卓版 地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
地铁跑酷黑白水下城魔改版本 3.9.0 安卓版