命名实体识别(NER)简介及使用指南
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
命名实体识别(Named Entity Recognition,简称NER)是一种文本处理技术,用于识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
NER在信息抽取中扮演着重要的角色,它可以帮助我们从文本中提取出具有特定意义的实体,如人名、地名、组织机构名等,为后续的文本分析和理解提供基础数据。
安装
详见: 数据标注工具 doccano | 文本分类(Text Classification)
数据准备
上传的文件为txt格式,每一行为一条待标注文本。示例:
corpus.txt 随便找了几个,一般都是垂直领域的数据标注
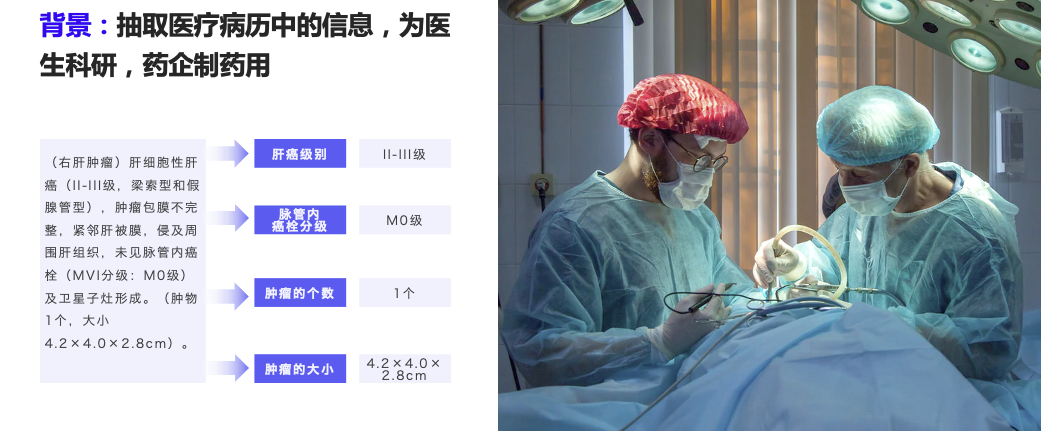
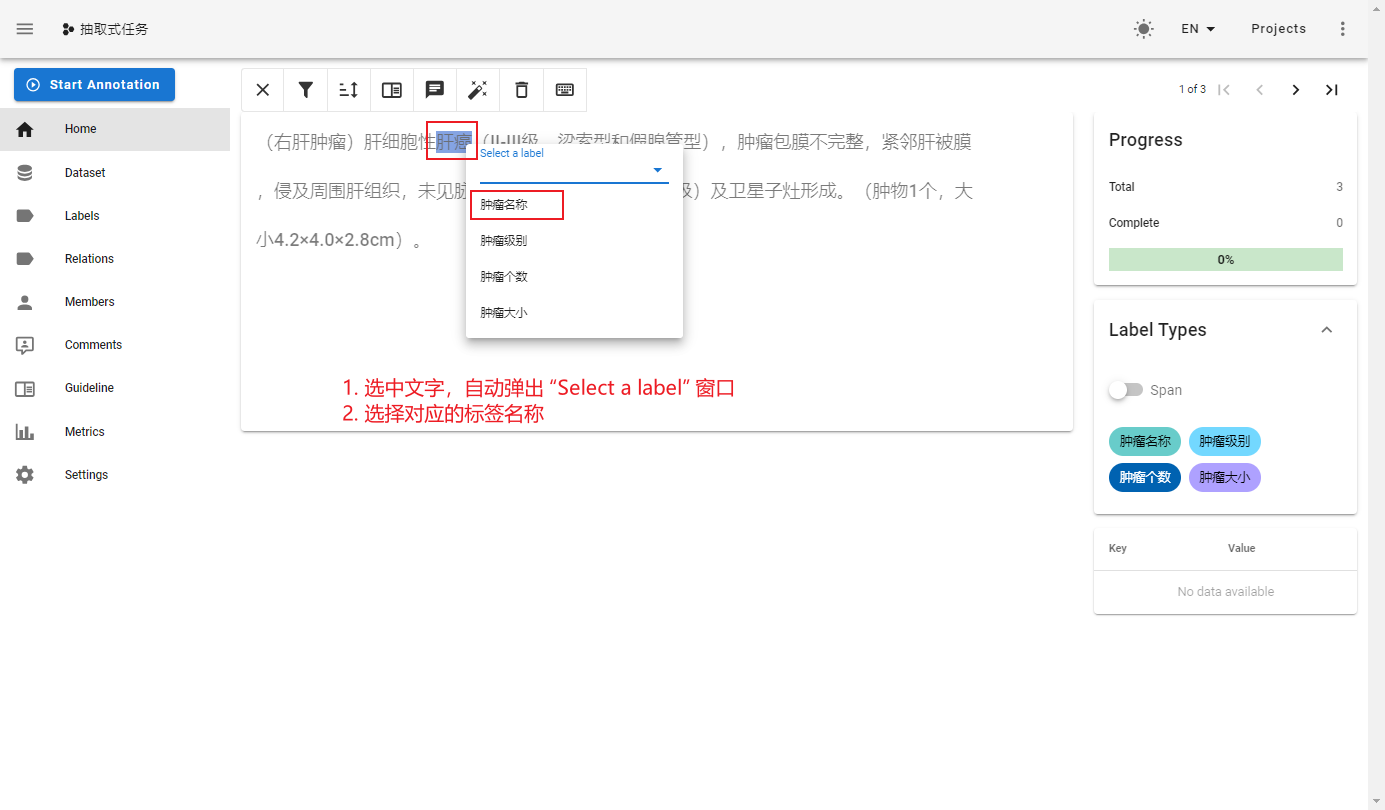
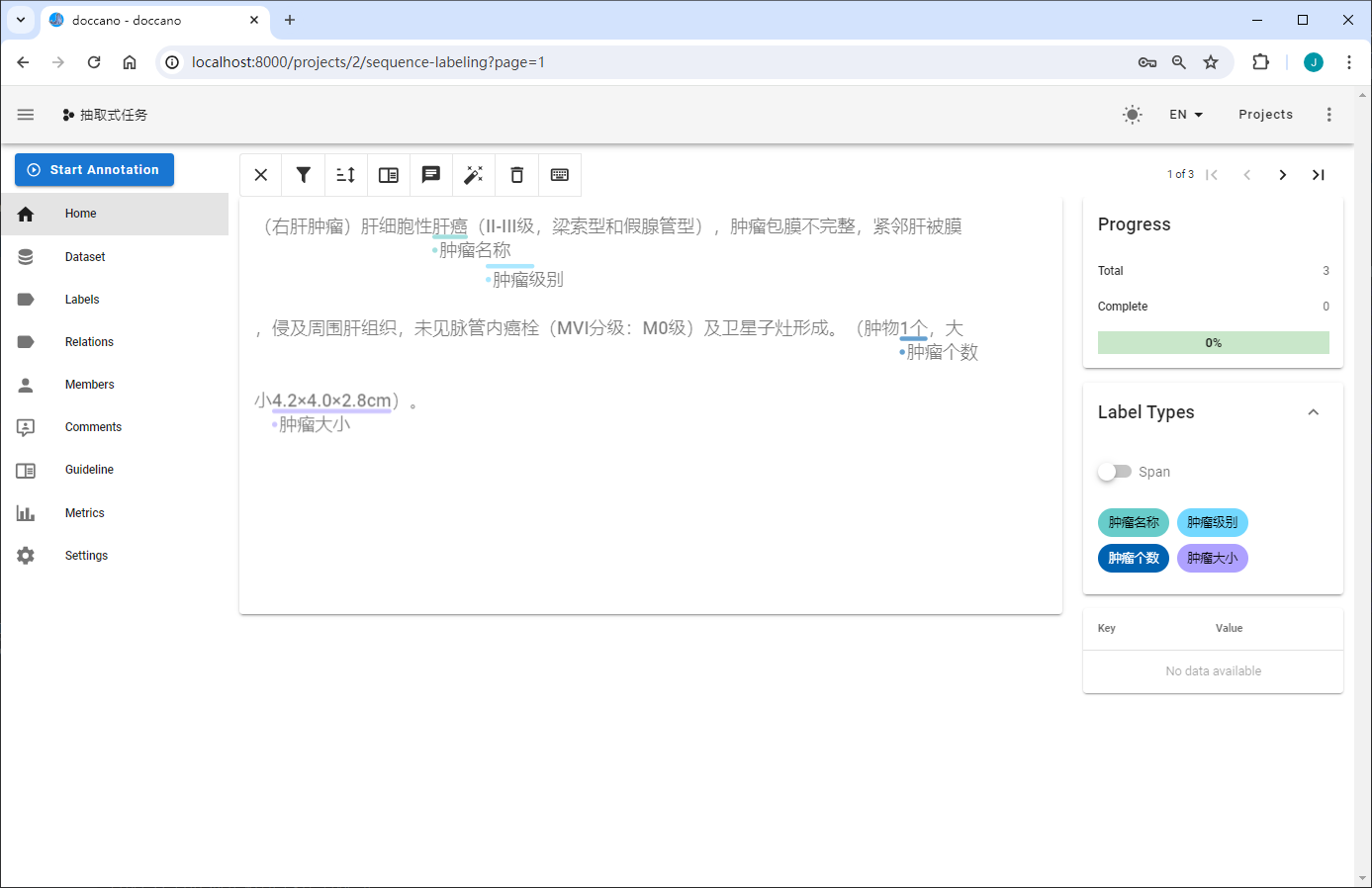
(右肝肿瘤)肝细胞性肝癌(II-III级,梁索型和假腺管型),肿瘤包膜不完整,紧邻肝被膜,侵及周围肝组织,未见脉管内癌栓(MVI分级:M0级)及卫星子灶形成。(肿物1个,大小4.2×4.0×2.8cm)。
患者20天前无明显诱因出现左侧胸背部持续性疼痛,于2025.02.01下城区中西医结合医院查胸部CT平扫示:右下肺少许炎症;肺气肿;慢性胰腺炎;建议追踪复查
双肺透亮度可,左下肺背段见一类圆开/结节影,大小约27X28mm,周围可见片状密度增高影,病变局部与胸膜粘连
创建项目
UIE支持抽取与分类两种类型的任务。根据实际需要创建一个新的项目:
-
抽取式任务项目创建
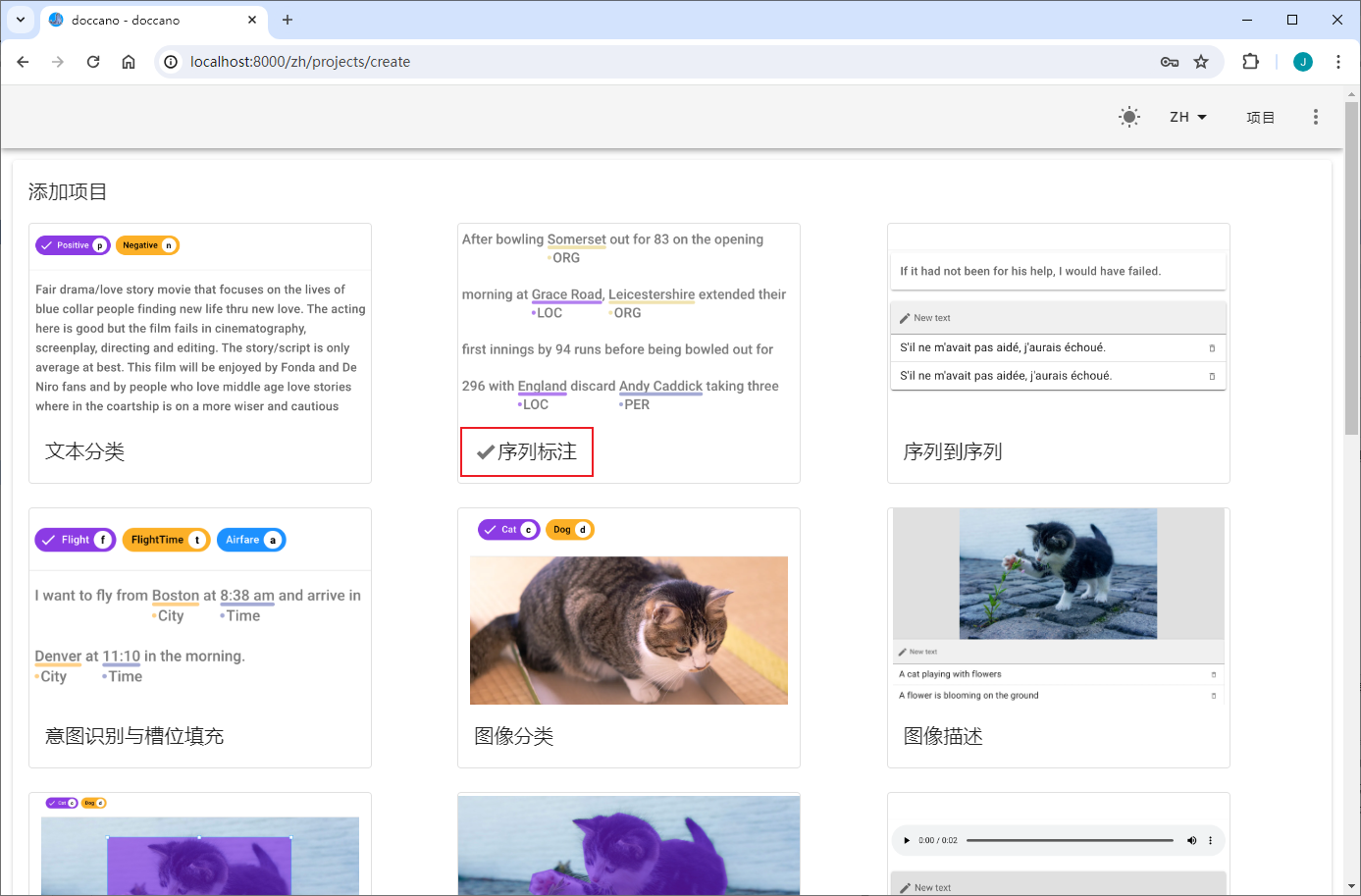
适配命名实体识别、关系抽取、事件抽取、评价观点抽取等任务
-
分类式任务项目创建
适配文本分类、句子级情感倾向分类等任务
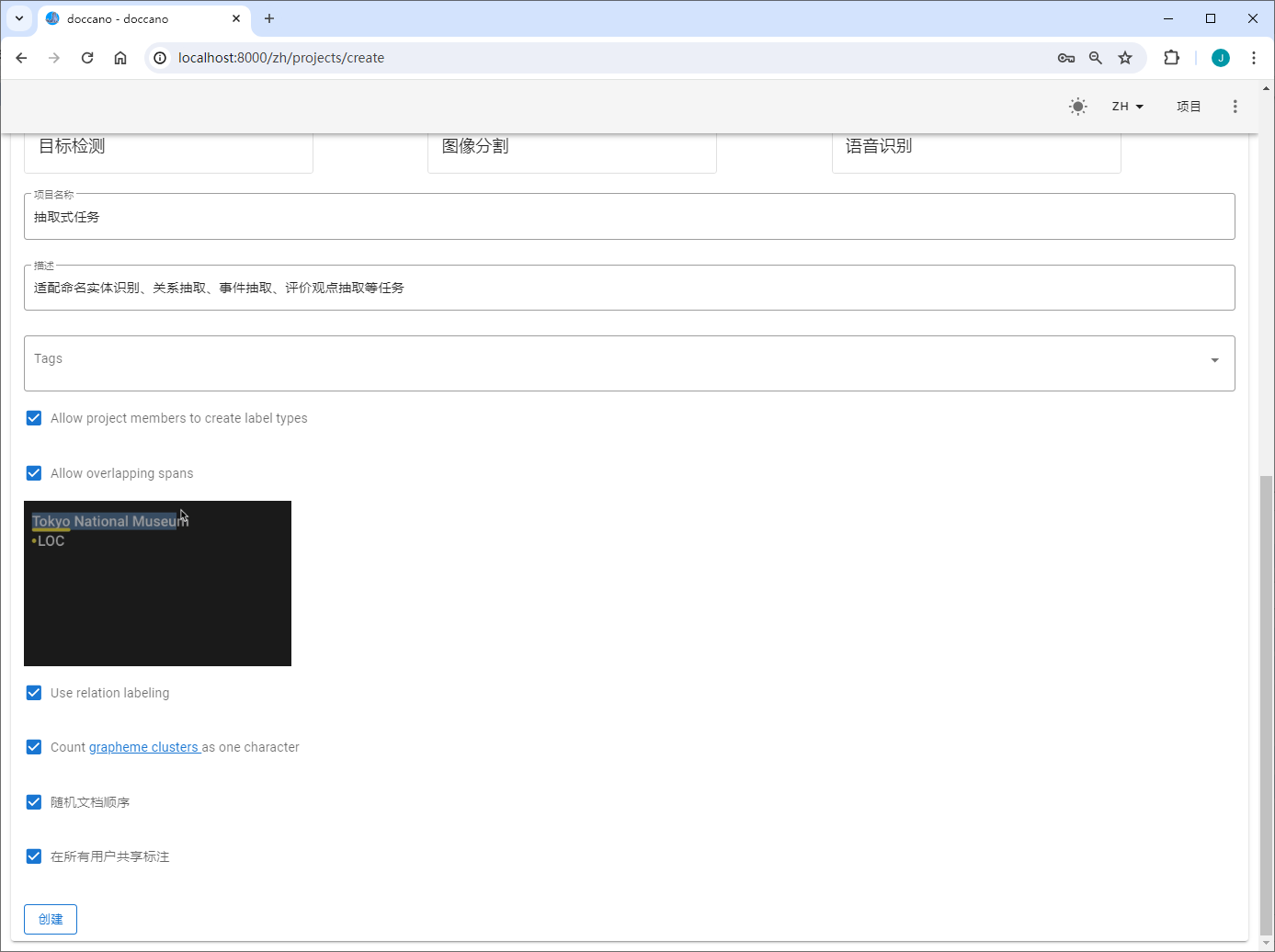
创建抽取式任务
上传
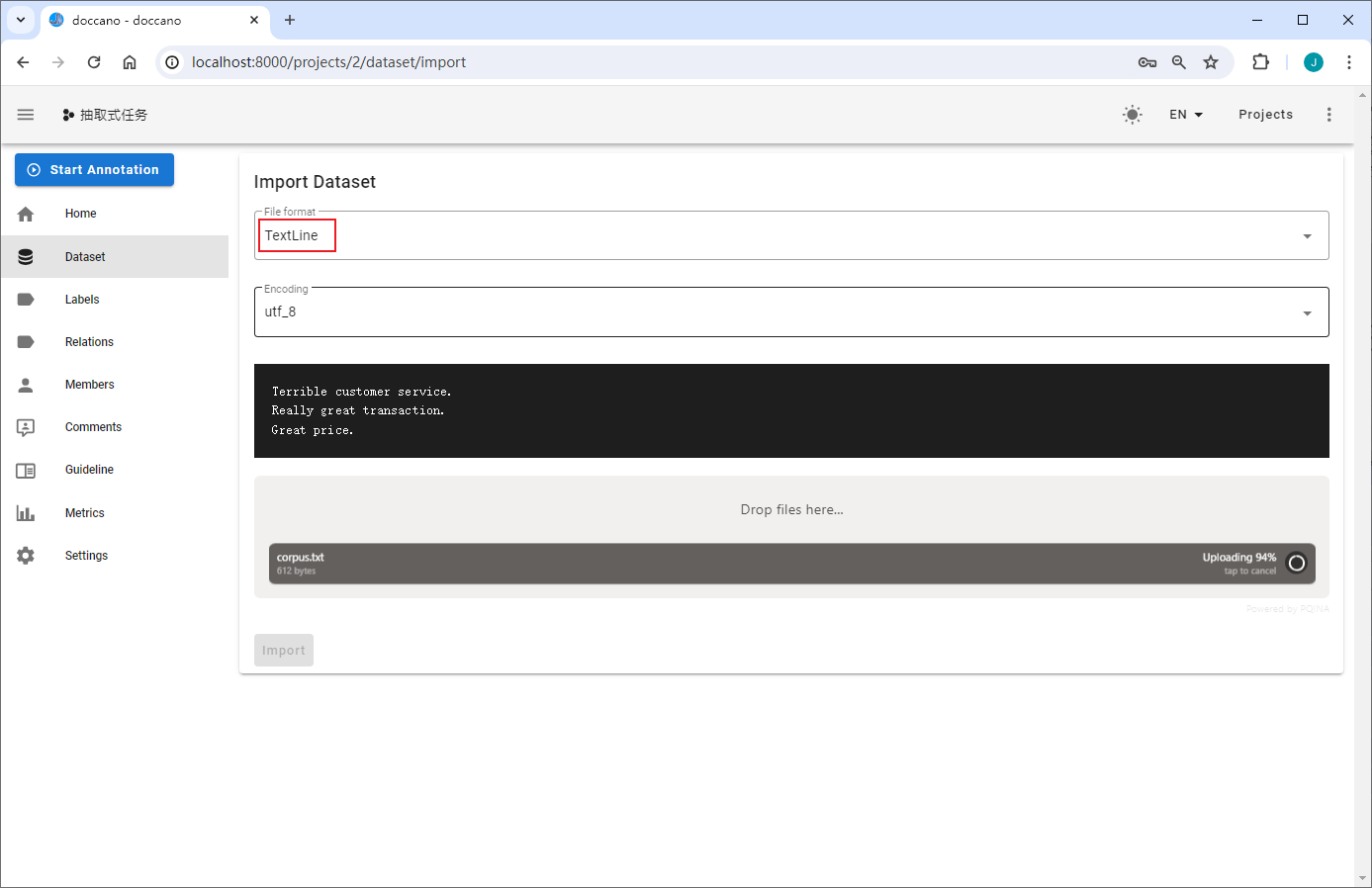
NOTE:doccano支持TextFile、TextLine、JSONL和CoNLL四种数据上传格式,UIE定制训练中统一使用TextLine这一文件格式,即上传的文件需要为txt格式,且在数据标注时,该文件的每一行待标注文本显示为一页内容。
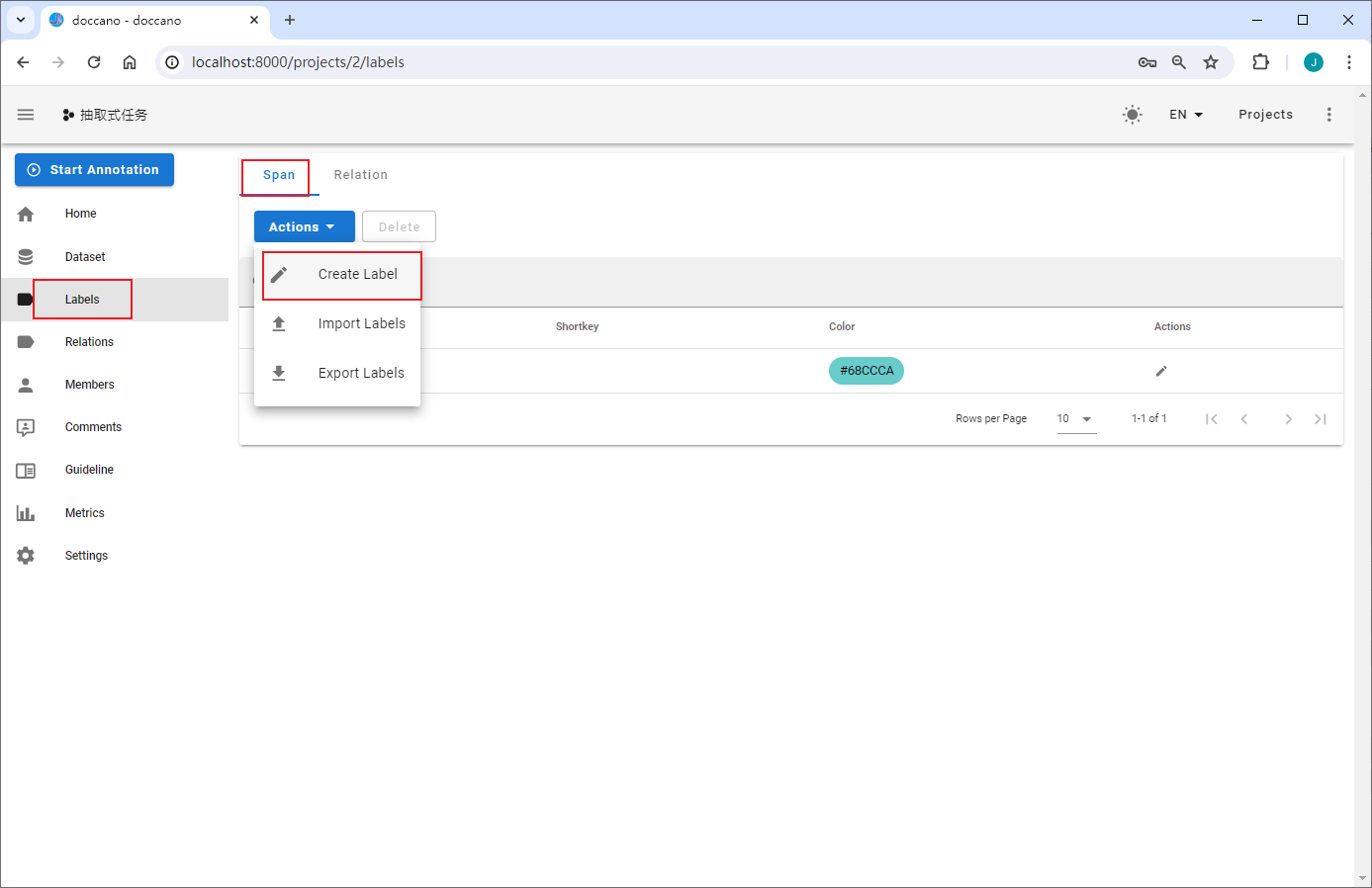
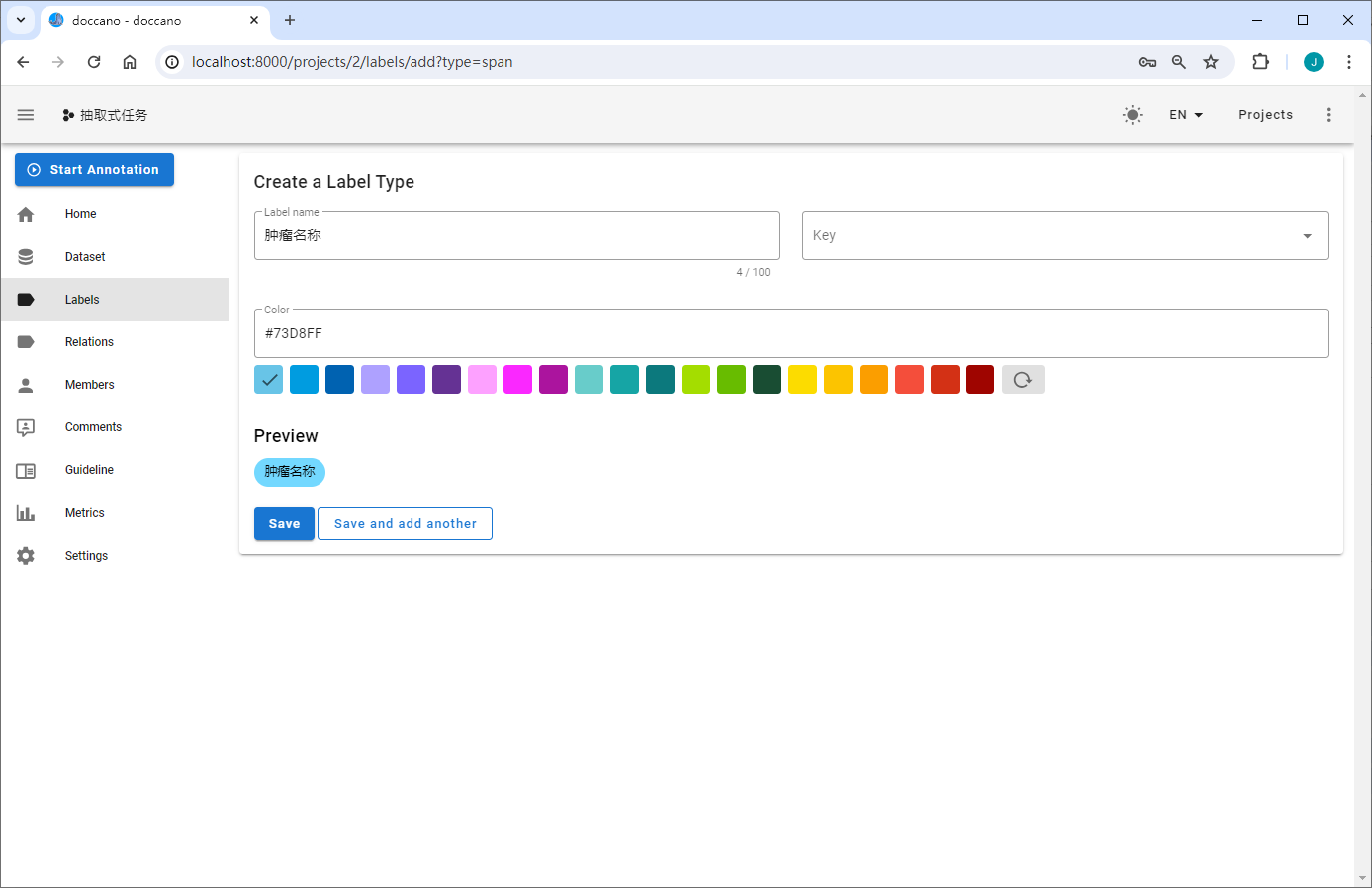
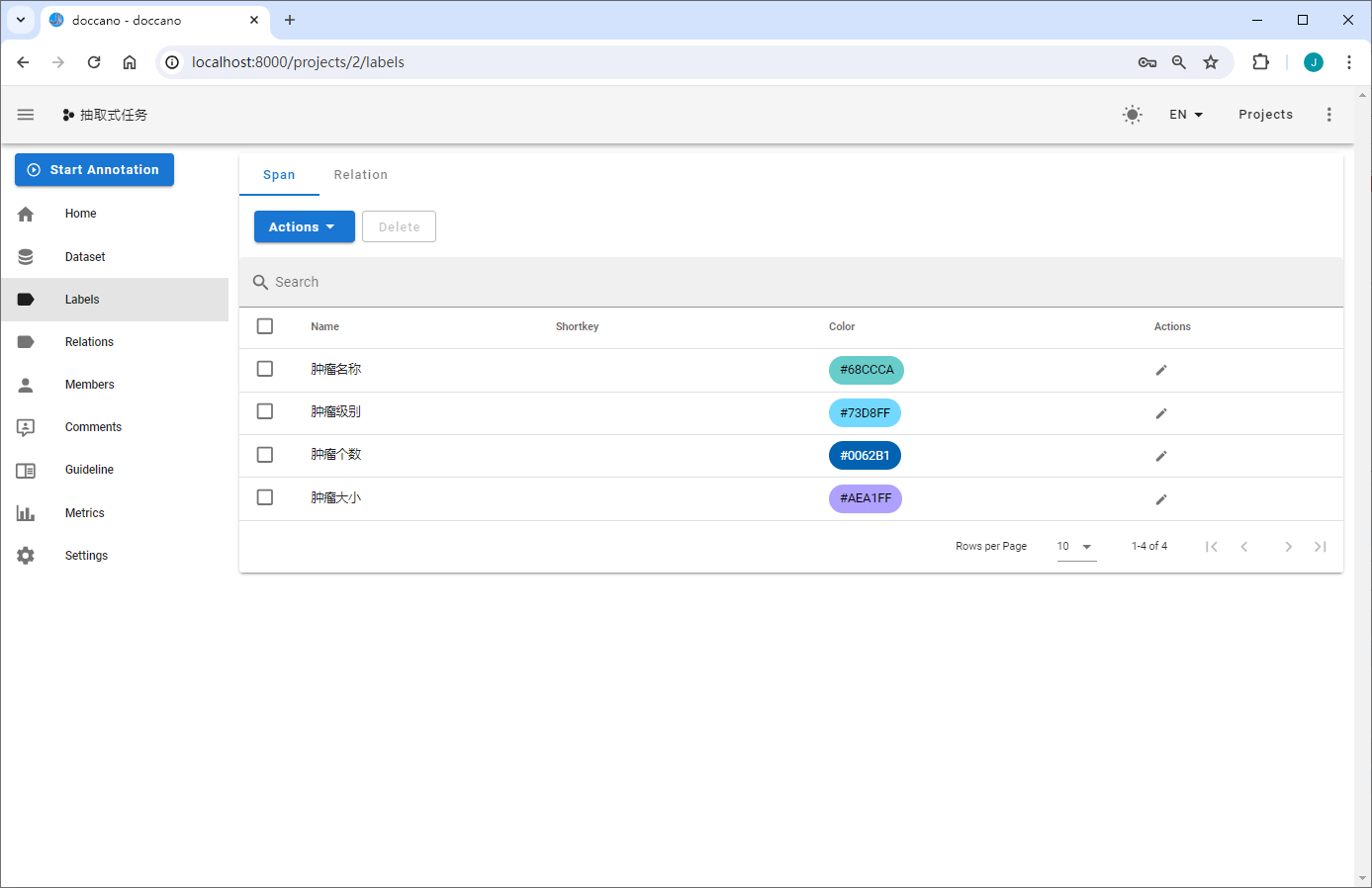
定义标签
构建抽取式任务标签
抽取式任务包含Span与Relation两种标签类型。Span指原文本中的目标信息片段,如实体识别中某个类型的实体,事件抽取中的触发词和论元;Relation指原文本中Span之间的关系,如关系抽取中两个实体(Subject&Object)之间的关系,事件抽取中论元和触发词之间的关系。
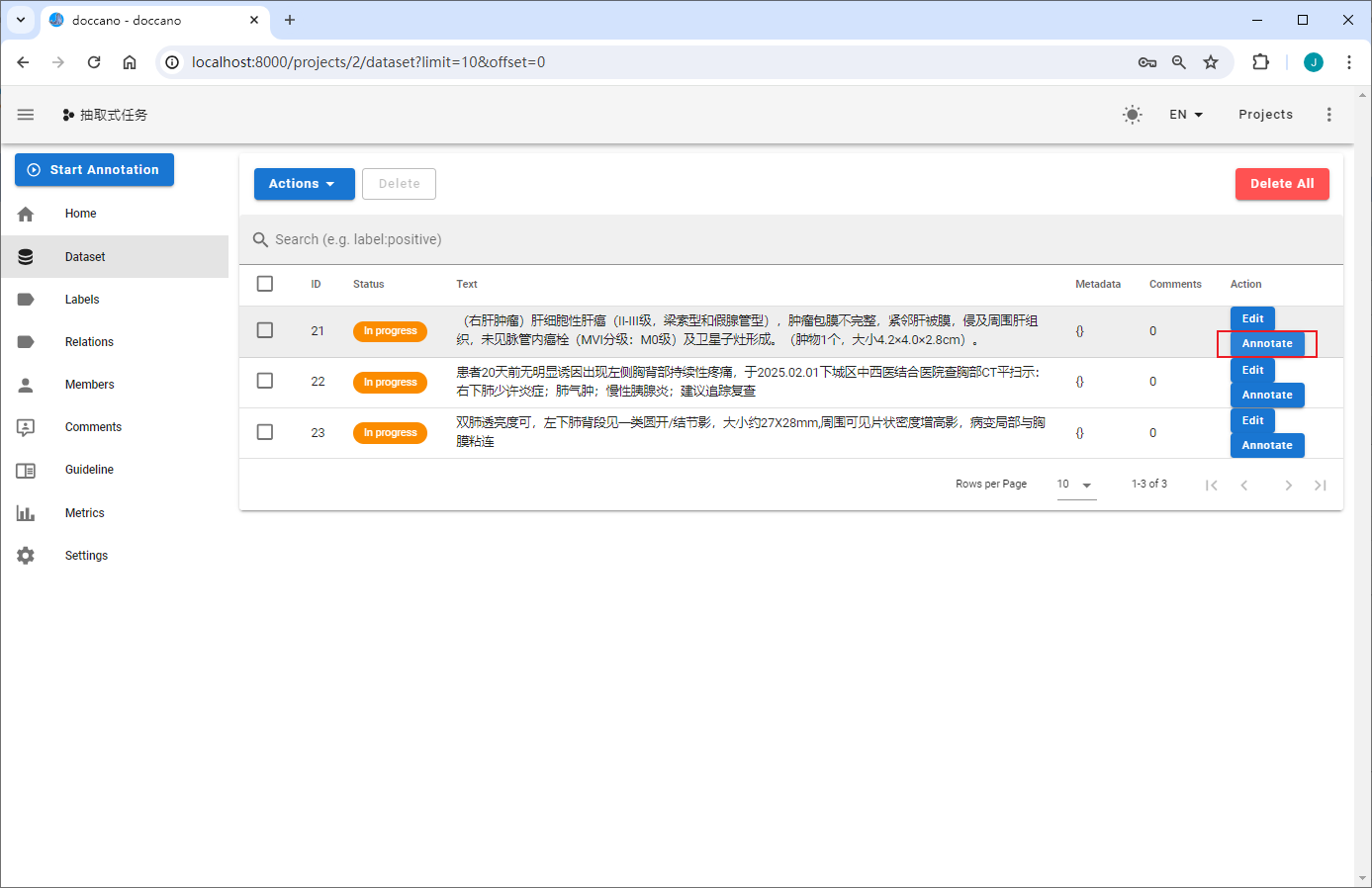
以 corpus.txt 中的第一条数据为例(医疗场景-专病结构化):
任务标注
命名实体识别
导出数据
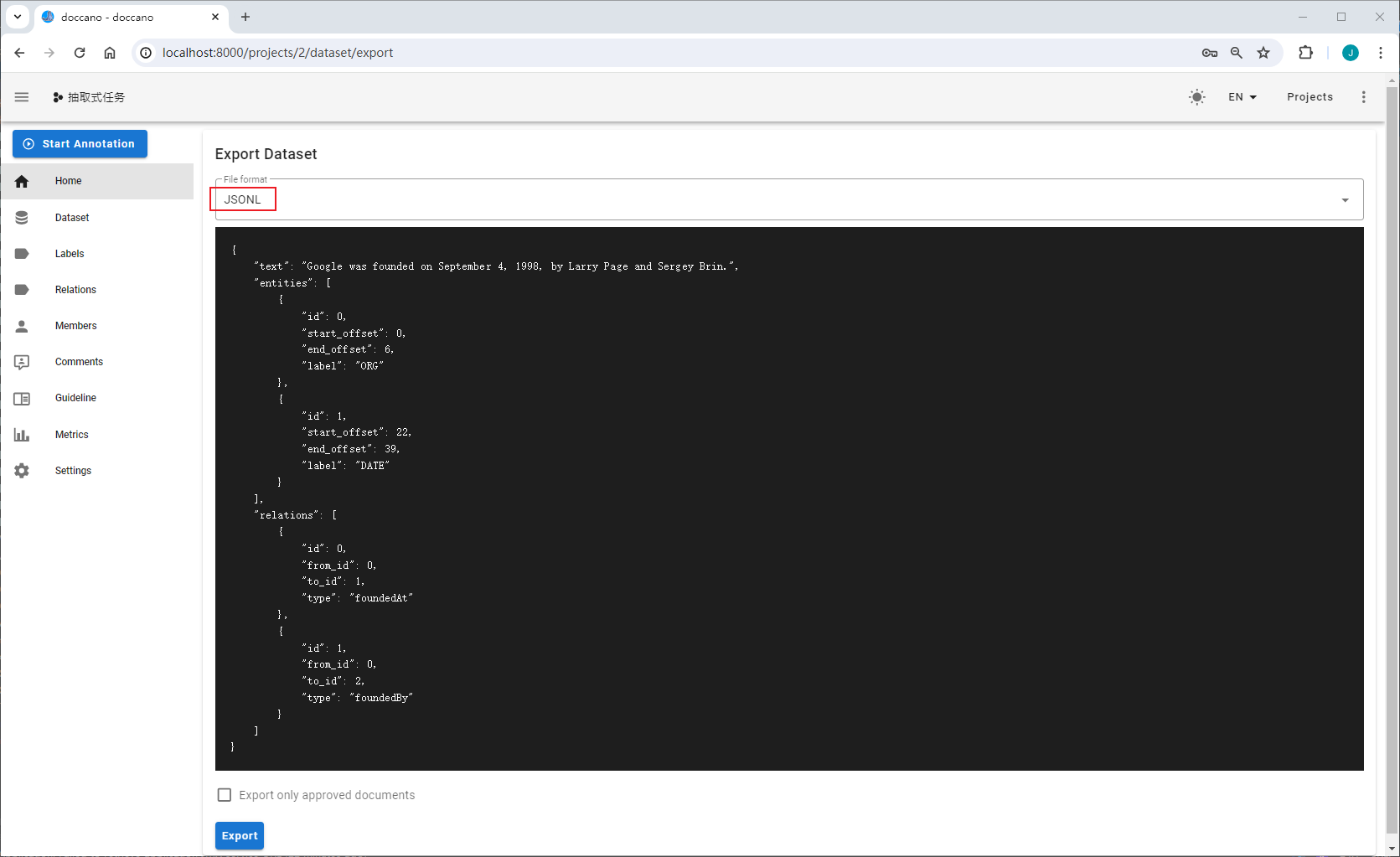
选择导出的文件类型为JSONL(relation),导出数据示例:
查看数据
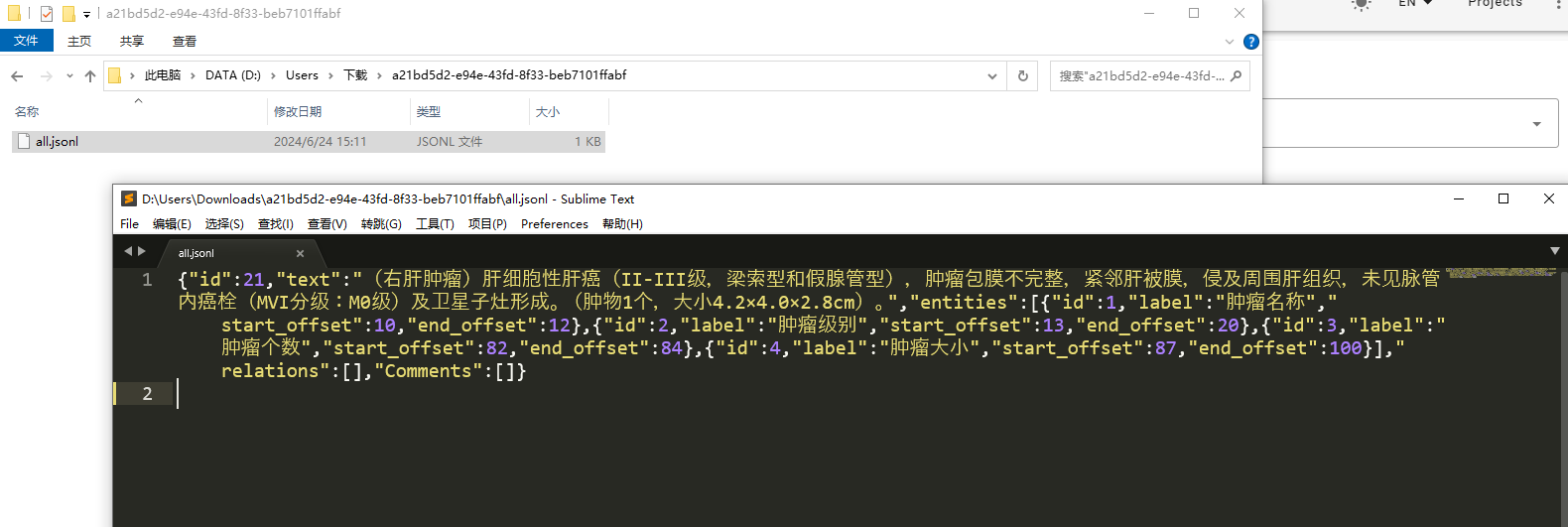
标注数据保存在同一个文本文件中,每条样例占一行且存储为json格式,其包含以下字段:
- id: 样本在数据集中的唯一标识ID。
- text: 原始文本数据。
-
entities: 数据中包含的Span标签,每个Span标签包含四个字段:
- id: Span在数据集中的唯一标识ID。
- start_offset: Span的起始token在文本中的下标。
- end_offset: Span的结束token在文本中下标的下一个位置。
- label: Span类型。
-
relations: 数据中包含的Relation标签,每个Relation标签包含四个字段:
- id: (Span1, Relation, Span2)三元组在数据集中的唯一标识ID,不同样本中的相同三元组对应同一个ID。
- from_id: Span1对应的标识ID。
- to_id: Span2对应的标识ID。
- type: Relation类型。
 战火与永恒破解版内置菜单最新版 v1.3.0 安卓版
战火与永恒破解版内置菜单最新版 v1.3.0 安卓版 辐射避难所Online无限旧货币版下载 v5.0.50 安卓版
辐射避难所Online无限旧货币版下载 v5.0.50 安卓版 库迪咖啡最新版
库迪咖啡最新版 苏门答腊公交车模拟器无限金币版下载 v3.5 安卓版
苏门答腊公交车模拟器无限金币版下载 v3.5 安卓版 胡萝卜逃亡
胡萝卜逃亡 修仙家族模拟器手机版
修仙家族模拟器手机版 快看天气最新版
快看天气最新版 无尽飞剑
无尽飞剑 租车帮
租车帮 U号租官方版
U号租官方版 破晓序列0.1折版下载 v2.5.1 安卓版
破晓序列0.1折版下载 v2.5.1 安卓版 十二分钟手机版
十二分钟手机版 最佳卡车司机2内置作弊菜单版下载 v4.3 安卓版
最佳卡车司机2内置作弊菜单版下载 v4.3 安卓版 像素火影干柿鬼鲛版
像素火影干柿鬼鲛版




















- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
企鹅岛 官方正版中文版
- 4
捕鱼大世界 无限金币版
- 5
烦人的村民 手机版
- 6
球球英雄 手游
- 7
情商天花板 2024最新版
- 8
内蒙打大a真人版
- 9
跳跃之王手游
- 10
蛋仔派对 国服版本
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 烦人的村民 手机版
烦人的村民 手机版 球球英雄 手游
球球英雄 手游 情商天花板 2024最新版
情商天花板 2024最新版 内蒙打大a真人版
内蒙打大a真人版 跳跃之王手游
跳跃之王手游 蛋仔派对 国服版本
蛋仔派对 国服版本 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 挂机小铁匠游戏 122 安卓版
挂机小铁匠游戏 122 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 死神之影2游戏 0.42.0 安卓版
死神之影2游戏 0.42.0 安卓版 跨越奔跑大师游戏 0.1 安卓版
跨越奔跑大师游戏 0.1 安卓版 灵魂潮汐手游 0.45.3 安卓版
灵魂潮汐手游 0.45.3 安卓版 旋转陀螺多人对战游戏 1.3.1 安卓版
旋转陀螺多人对战游戏 1.3.1 安卓版 Escapist游戏 1.1 安卓版
Escapist游戏 1.1 安卓版 地铁跑酷黑白水下城魔改版本 3.9.0 安卓版
地铁跑酷黑白水下城魔改版本 3.9.0 安卓版